當您需要同時運行多個機器學習模型并進行推理時,可以使用模型服務網格部署和管理多模型推理服務。模型服務網格基于KServe ModelMesh實現,針對大容量、高密度和頻繁變化的模型用例進行了優化,可以智能地將模型加載到內存中或從內存中卸載,以在響應性和計算之間取得平衡,簡化多模型推理服務的部署和運維,提高推理效率和性能。
前提條件
已添加集群到ASM實例,且ASM實例版本為1.18.0.134及以上。
已為集群添加入口網關。具體操作,請參見創建入口網關。
本文使用ASM入口網關作為集群網關,網關名稱為默認的ingressgateway,開放8008端口,協議為HTTP。
功能介紹
模型服務網格提供了以下功能:
功能 | 說明 |
緩存管理 |
|
智能放置和加載 |
|
彈性 | 失敗的模型加載會在不同的Pod中自動重試。 |
操作簡便性 | 自動和無縫地處理滾動模型更新。 |
步驟一:在ASM中開啟ModelMesh功能
登錄ASM控制臺,在左側導航欄,選擇。
在網格管理頁面,單擊目標實例名稱,然后在左側導航欄,選擇。
在KServe on ASM頁面,單擊安裝模型服務網格, 開啟ModelMesh功能。
注意:KServe依賴于CertManager,安裝KServe會自動安裝CertManager組件。如需使用自建CertManager,請關閉在集群中自動安裝CertManager組件。
等待幾分鐘就緒之后, 在ACK集群對應的KubeConfig環境下,執行以下命令,確認ServingRuntime資源是否可用。
kubectl get servingruntimes -n modelmesh-serving預期輸出:
NAME DISABLED MODELTYPE CONTAINERS AGE mlserver-1.x sklearn mlserver 1m ovms-1.x openvino_ir ovms 1m torchserve-0.x pytorch-mar torchserve 1m triton-2.x keras triton 1mServingRuntime定義為一個或多個特定模型格式提供服務的Pod模板,根據部署的模型的框架,會自動提供相應的Pod。
目前默認包含的運行時及支持的模型格式如下。詳細信息,請參見supported-model-formats。如果這些模型服務器不能滿足您的所有特定要求,可以自定義模型運行時。具體操作,請參見使用模型服務網格自定義模型運行時。
模型服務運行時
支持的模型框架
mlserver-1.x
sklearn、xgboost、lightgbm
ovms-1.x
openvino_ir、onnx
torchserve-0.x
pytorch-mar
triton-2.x
tensorflow、pytorch、onnx、tensorrt
步驟二:配置ASM環境
從Kubernetes集群同步命名空間到ASM中, 具體操作,請參見從數據平面集群同步自動注入標簽至ASM實例。 同步之后, 確認命名空間modelmesh-serving已經存在。
創建入口網關規則。
使用以下內容,創建grpc-gateway.yaml。
apiVersion: networking.istio.io/v1beta1 kind: Gateway metadata: name: grpc-gateway namespace: modelmesh-serving spec: selector: istio: ingressgateway servers: - hosts: - '*' port: name: grpc number: 8008 protocol: GRPC在ASM集群(實例)對應的KubeConfig環境下,執行以下命令,創建網關規則。
kubectl apply -f grpc-gateway.yaml
創建虛擬服務。
使用以下內容,創建vs-modelmesh-serving-service.yaml。
apiVersion: networking.istio.io/v1beta1 kind: VirtualService metadata: name: vs-modelmesh-serving-service namespace: modelmesh-serving spec: gateways: - grpc-gateway hosts: - '*' http: - match: - port: 8008 name: default route: - destination: host: modelmesh-serving port: number: 8033在ASM集群(實例)對應的KubeConfig環境下,執行以下命令,創建虛擬服務。
kubectl apply -f vs-modelmesh-serving-service.yaml
配置gRPCJSON轉碼器。
使用以下內容,創建grpcjsontranscoder-for-kservepredictv2.yaml。
apiVersion: istio.alibabacloud.com/v1beta1 kind: ASMGrpcJsonTranscoder metadata: name: grpcjsontranscoder-for-kservepredictv2 namespace: istio-system spec: builtinProtoDescriptor: kserve_predict_v2 isGateway: true portNumber: 8008 workloadSelector: labels: istio: ingressgateway在ASM集群(實例)對應的KubeConfig環境下,執行以下命令,部署gRPC-Json-Transcoder。
kubectl apply -f grpcjsontranscoder-for-kservepredictv2.yaml使用以下內容,創建grpcjsontranscoder-increasebufferlimit.yaml,設置
per_connection_buffer_limit_bytes,以提升響應的大小。apiVersion: networking.istio.io/v1alpha3 kind: EnvoyFilter metadata: labels: asm-system: "true" manager: asm-voyage provider: asm name: grpcjsontranscoder-increasebufferlimit namespace: istio-system spec: configPatches: - applyTo: LISTENER match: context: GATEWAY listener: portNumber: 8008 proxy: proxyVersion: ^1.* patch: operation: MERGE value: per_connection_buffer_limit_bytes: 100000000 workloadSelector: labels: istio: ingressgateway在ASM集群(實例)對應的KubeConfig環境下,執行以下命令,部署EnvoyFilter。
kubectl apply -f grpcjsontranscoder-increasebufferlimit.yaml
步驟三:部署模型示例
創建存儲類StorageClass。更多信息,請參見使用NAS動態存儲卷。
登錄容器服務管理控制臺,在左側導航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在存儲類頁面右上角,單擊創建,配置如下信息,然后創建。
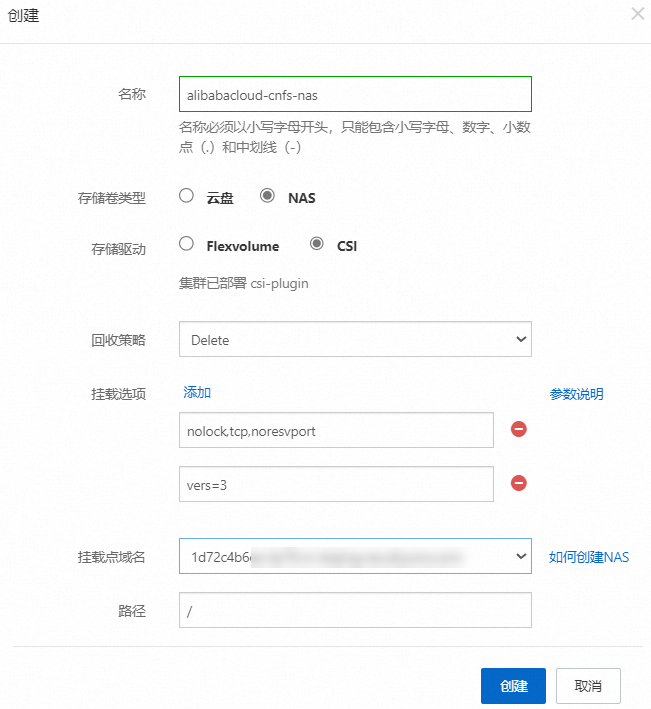
創建存儲聲明PVC。
使用以下內容,創建存儲聲明my-models-pvc.yaml。
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: my-models-pvc namespace: modelmesh-serving spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi storageClassName: alibabacloud-cnfs-nas volumeMode: Filesystem在ACK集群對應的KubeConfig環境下,執行以下命令,創建存儲聲明。
kubectl apply -f my-models-pvc.yaml執行以下命令,查看modelmesh-serving命名空間下的PVC。
kubectl get pvc -n modelmesh-serving預期輸出:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-models-pvc Bound nas-379c32e1-c0ef-43f3-8277-9eb4606b53f8 1Gi RWX alibabacloud-cnfs-nas 2h
創建Pod以訪問PVC。
為了使用新的PVC,需要將其作為卷安裝到Kubernetes Pod,然后使用該Pod將模型文件上傳到持久卷。
使用以下內容,創建pvc-access.yaml。
以下YAML表示創建一個pvc-access Pod,并要求Kubernetes控制器通過指定
“my-models-pvc”來聲明之前請求的PVC。apiVersion: v1 kind: Pod metadata: name: "pvc-access" spec: containers: - name: main image: ubuntu command: ["/bin/sh", "-ec", "sleep 10000"] volumeMounts: - name: "my-pvc" mountPath: "/mnt/models" volumes: - name: "my-pvc" persistentVolumeClaim: claimName: "my-models-pvc"在ACK集群對應的KubeConfig環境下,執行以下命令,創建Pod。
kubectl apply -n modelmesh-serving -f pvc-access.yaml確認pvc-access Pod處于運行狀態。
kubectl get pods -n modelmesh-serving | grep pvc-access預期輸出:
pvc-access 1/1 Running 0 51m
將模型存儲在持久卷上。
將AI模型添加到存儲卷中。本文將使用scikit-learn訓練的MNIST手寫數字字符識別模型。您可以從kserve/modelmesh-minio-examples倉庫下載mnist-svm.joblib模型文件的副本。
在ACK集群對應的KubeConfig環境下,執行以下命令,將mnist-svm.joblib模型文件復制到pvc-access Pod的
/mnt/models文件夾中。kubectl -n modelmesh-serving cp mnist-svm.joblib pvc-access:/mnt/models/執行以下命令,確認Model已經加載成功。
kubectl -n modelmesh-serving exec -it pvc-access -- ls -alr /mnt/models/預期輸出:
-rw-r--r-- 1 501 staff 344817 Oct 30 11:23 mnist-svm.joblib
部署推理服務。
使用以下內容,創建sklearn-mnist.yaml。
apiVersion: serving.kserve.io/v1beta1 kind: InferenceService metadata: name: sklearn-mnist namespace: modelmesh-serving annotations: serving.kserve.io/deploymentMode: ModelMesh spec: predictor: model: modelFormat: name: sklearn storage: parameters: type: pvc name: my-models-pvc path: mnist-svm.joblib在ACK集群對應的KubeConfig環境下,執行以下命令,部署sklearn-mnist推理服務。
kubectl apply -f sklearn-mnist.yaml等待幾十秒后(時間取決于鏡像拉取速度),執行以下命令,查看sklearn-mnist推理服務是否部署成功。
kubectl get isvc -n modelmesh-serving預期輸出:
NAME URL READY sklearn-mnist grpc://modelmesh-serving.modelmesh-serving:8033 True
運行推理服務。
使用
curl命令發送推理請求到sklearn-mnist模型。數據數組表示待分類的數字圖像掃描中64個像素的灰度值。MODEL_NAME="sklearn-mnist" ASM_GW_IP="ASM網關IP地址" curl -X POST -k "http://${ASM_GW_IP}:8008/v2/models/${MODEL_NAME}/infer" -d '{"inputs": [{"name": "predict", "shape": [1, 64], "datatype": "FP32", "contents": {"fp32_contents": [0.0, 0.0, 1.0, 11.0, 14.0, 15.0, 3.0, 0.0, 0.0, 1.0, 13.0, 16.0, 12.0, 16.0, 8.0, 0.0, 0.0, 8.0, 16.0, 4.0, 6.0, 16.0, 5.0, 0.0, 0.0, 5.0, 15.0, 11.0, 13.0, 14.0, 0.0, 0.0, 0.0, 0.0, 2.0, 12.0, 16.0, 13.0, 0.0, 0.0, 0.0, 0.0, 0.0, 13.0, 16.0, 16.0, 6.0, 0.0, 0.0, 0.0, 0.0, 16.0, 16.0, 16.0, 7.0, 0.0, 0.0, 0.0, 0.0, 11.0, 13.0, 12.0, 1.0, 0.0]}}]}'JSON響應如下,表示推斷掃描的數字是
8。{ "modelName": "sklearn-mnist__isvc-3c10c62d34", "outputs": [ { "name": "predict", "datatype": "INT64", "shape": [ "1", "1" ], "contents": { "int64Contents": [ "8" ] } } ] }
相關文檔
當您遇到多模型部署時存在差異化運行時環境需求,或者需要優化模型推理效率、控制資源分配的問題時,可以使用模型服務網格自定義模型運行時,通過精細配置運行環境,確保每個模型都能在最適宜的條件下執行。具體操作,請參見使用模型服務網格自定義模型運行時。
當您需要處理大量自然語言數據或希望建立復雜的語言理解系統時,可以將大語言模型轉化為推理服務。具體操作,請參見將大語言模型轉化為推理服務。
當您的Pod在運行時出現異常,請參見Pod異常問題排查。