本文介紹如何針對資訊聚合類業務場景搭建基于云消息隊列 Kafka 版和實時計算Flink的實時數倉。
場景描述
本文首先介紹什么是實時數倉以及相關技術架構,接著介紹資訊聚合類業務的典型場景及其業務目標,并據此設計了相應的技術架構。然后介紹如何部署基礎環境和搭建實時數倉,并介紹業務系統如何使用實時數倉。
解決的問題
- 通過云消息隊列 Kafka 版和實時計算Flink實現實時數據處理和數據流。
- 通過云消息隊列 Kafka 版和實時計算Flink實現實時數據分析。
- 通過云消息隊列 Kafka 版和實時計算Flink實現事件觸發。
部署架構圖
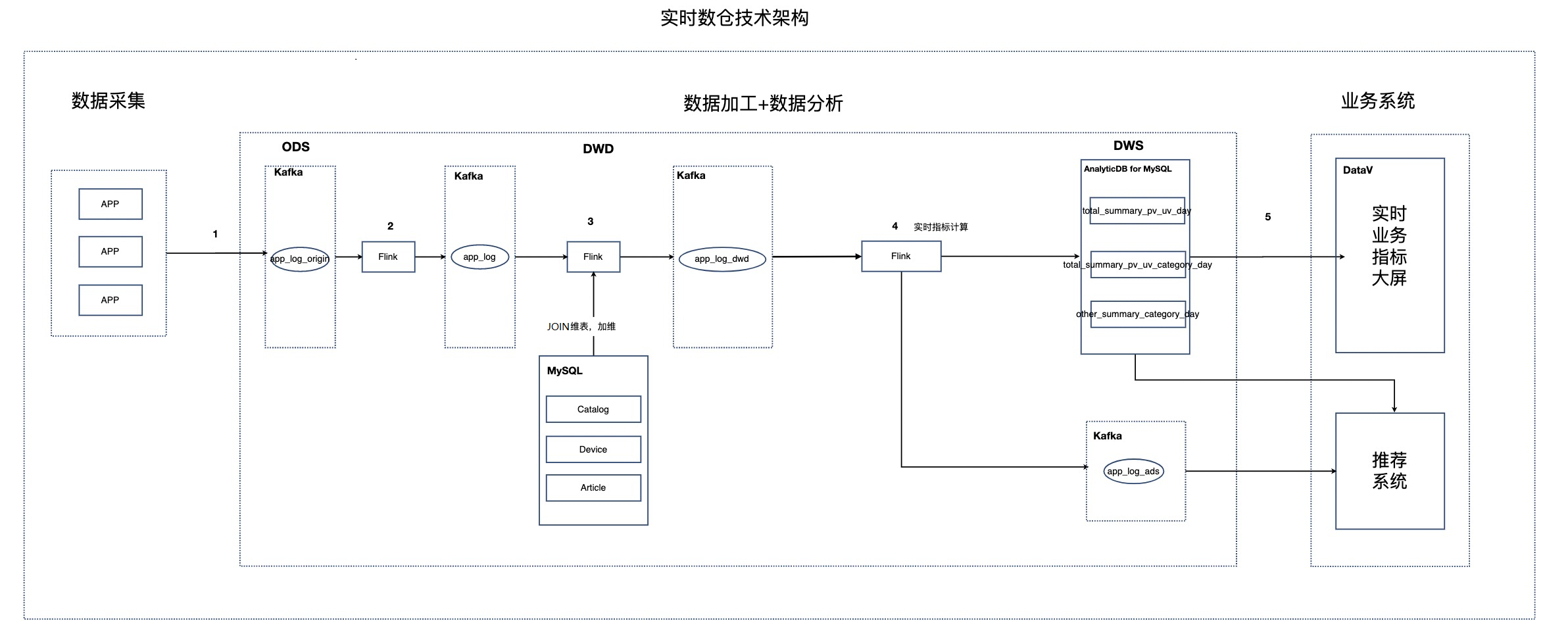
選用的產品
- 云消息隊列 Kafka 版
云消息隊列 Kafka 版是阿里云基于Apache Kafka構建的高吞吐量、高可擴展性的分布式消息隊列服務,廣泛用于日志收集、監控數據聚合、流式數據處理、在線和離線分析等,是大數據生態中不可或缺的產品之一,阿里云提供全托管服務,免部署、免運維,更專業、更可靠、更安全。
更多關于云消息隊列 Kafka 版的介紹,參見云消息隊列 Kafka 版產品詳情頁。
- 實時計算
實時計算(Alibaba Cloud Realtime Compute)是阿里云提供的基于Apache Flink構建的企業級大數據計算平臺。在PB級別的數據集上可以支持亞秒級別的處理延時,賦能用戶標準實時數據處理流程和行業解決方案;支持Datastream API作業開發,提供了批流統一的Flink SQL,簡化BI場景下的開發;可與用戶已使用的大數據組件無縫對接,更多增值特性助力企業實時化轉型。
更多關于實時計算的介紹,參見實時計算產品詳情頁。
- DataV數據可視化
DataV旨在讓更多的人看到數據可視化的魅力,幫助非專業的工程師通過圖形化的界面輕松搭建專業水準的可視化應用,滿足您會議展覽、業務監控、風險預警、地理信息分析等多種業務的展示需求。
更多關于阿里云DataV數據可視化的介紹,參見DataV數據可視化產品詳情頁。
- 專有網絡VPC
專有網絡VPC幫助您基于阿里云構建出一個隔離的網絡環境,并可以自定義IP地址范圍、網段、路由表和網關等;此外,也可以通過專線、VPN、GRE等連接方式實現云上VPC與傳統IDC的互聯,構建混合云業務。
更多關于專有網絡VPC的介紹,參見專有網絡VPC產品詳情頁。
- 云數據庫RDS
阿里云關系型數據庫RDS(Relational Database Service)是一種穩定可靠、可彈性伸縮的在線數據庫服務。基于阿里云分布式文件系統和SSD盤高性能存儲,RDS支持MySQL、SQL Server、PostgreSQL和MariaDB引擎,并且提供了容災、備份、恢復、監控、遷移等方面的全套解決方案,徹底解決數據庫運維的煩惱。
更多關于云數據庫RDS的介紹,參見云數據庫RDS產品文檔。
- 分析型數據庫MySQL版
分析型數據庫MySQL版(AnalyticDB for MySQL)是一種高并發低延時的PB級實時數據倉庫,兼容MySQL協議以及SQL:2003語法標準,可以毫秒級針對萬億級數據進行即時的多維分析透視和業務探索。
更多關于分析型數據庫MySQL版的介紹,參見分析型數據庫MySQL版產品詳情頁。
- 對象存儲OSS
阿里云對象存儲OSS(Object Storage Service),是阿里云提供的海量、安全、低成本、高可靠的云存儲服務。
更多關于對象存儲OSS的介紹,參見對象存儲OSS產品詳情頁。