倉內智能(公測)
通過AnalyticDB PostgreSQL版的PG_CATALOG.AI_GENERATE_TEXT(...)函數與部署在阿里云PAI模型在線服務(EAS)平臺中的LLM(大語言模型)服務進行交互,實現對語言的推理、分類、歸納、總結等。
背景信息
AIGC(Artificial Intelligence Generative Content)是一種新的人工智能技術,即人工智能生成內容。它基于機器學習和自然語言處理的技術,能夠自動產生文本、圖像、音頻等多種類型的內容。
AnalyticDB PostgreSQL版作為數據分析與輕量級AI一體化的平臺,可以幫助絕大多數中小型用戶在數據庫內部,閉環實現數據分析為主與AI應用為輔的訴求,為數據分析插上AI的翅膀。
AnalyticDB PostgreSQL版的AIGC倉內智能,提供人工智能文本生成(AI Text Generation)服務。使用LLM服務來生成(或推理)在風格、語氣和內容上與輸入數據相似的新文本。
前提條件
AnalyticDB PostgreSQL版實例的內核版本需滿足以下條件。如何查看實例內核版本,請參見查看內核小版本。
存儲彈性模式6.0版實例,內核版本需為v6.6.1.0及以上。
存儲彈性模式7.0版實例,內核版本需為v7.0.4.0及以上。
Serverless模式實例,內核版本需為cn.v2.1.1.5 及以上。
已開通與AnalyticDB PostgreSQL版實例同地域的PAI模型在線服務(EAS),且至少部署了一款LLM服務(如:通義千問大模型、ChatGLM、Llama2等)。本文以部署通義千問大模型為例。具體操作,請參見5分鐘操作EAS一鍵部署通義千問模型。
說明對中文文本進行推理、歸納、總結等操作時,建議首選通義千問模型。經與其他模型測試對比,通義千問模型在處理數據的響應時間、生成推理內容的準確度等方面,均有不俗的表現。
部署ChatGLM大語言模型的操作,請參見5分鐘使用EAS一鍵部署ChatGLM及LangChain應用。
部署Llama2大語言模型的操作,請參見Llama2-WebUI基于EAS的一鍵部署。
PG_CATALOG.AI_GENERATE_TEXT(...)函數介紹
語法
FUNCTION PG_CATALOG.AI_GENERATE_TEXT
(input_endpoint text,
input_token text,
input_prompt text,
input_additional_parms text)
RETURNS TEXT
......參數
參數 | 是否必填 | 描述 |
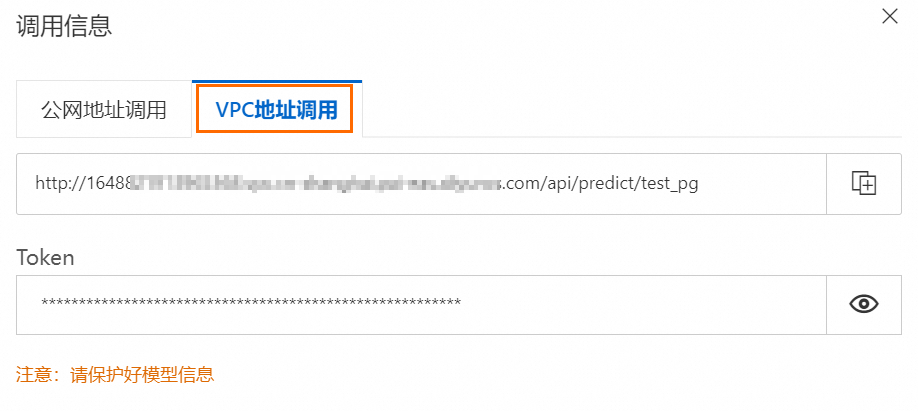
input_endpoint | 是 | 指定訪問部署在PAI-EAS平臺中的LLM服務時所需要的Endpoint。 Endpoint獲取方法:
|
input_token | 是 | 指定訪問部署在PAI-EAS平臺中的LLM服務時所需要的Token。 Token獲取方法:
|
input_prompt | 是 | 需要推理的文本內容。 |
input_additional_parms | 否 | 支持設置參數 格式:
如果不設置該參數,調用 |
示例
示例一:使用參數
input_prompt進行語言推理。SELECT PG_CATALOG.AI_GENERATE_TEXT('http://1648821****.vpc.cn-shanghai.pai-eas.aliyuncs.com/api/predict/test_pg', 'OGZiOGVkNTcwNTRiNzA0ODM1MGY0MTZhZGIwNT****', '浙江省的省會在哪里?', NULL) AS 答復;返回結果如下。
-[RECOND 1]--------------- 答復 | 浙江省的省會是杭州市。示例二:使用參數
input_additional_parms提供上下文,進行語言推理。加入相關的上下文,可以提高語言推理的準確性。本示例提供的上下文話題背景與省會相關,因此針對問題“江蘇呢?”,所得到的推論是“江蘇省的省會是南京”,而非與江蘇省相關的一些其它信息介紹。
SELECT PG_CATALOG.AI_GENERATE_TEXT('http://1648821****.vpc.cn-shanghai.pai-eas.aliyuncs.com/api/predict/test_pg', 'OGZiOGVkNTcwNTRiNzA0ODM1MGY0MTZhZGIwNT****', '江蘇呢?', '{ "history" : [ ["浙江的省會在哪里?", "浙江省的省會是杭州。"], ["遼寧的省會在哪里?", "遼寧省的省會是沈陽。"] ] }') as 答復;返回結果如下。
-[RECOND 1]------------- 答復 | 江蘇省的省會是南京。
最佳實踐:封裝函數AI_GENERATE_TEXT
每次在使用函數AI_GENERATE_TEXT時,都需要傳入較長內容的參數input_endpoint與input_token。不僅使用方式不夠簡潔,還會在應用程序中暴露敏感信息。建議自定義一個新的函數,將AI_GENERATE_TEXT進行封裝。這有利于:
簡化使用方式,同時屏蔽敏感信息。
可以對推理生成的內容,進行二次加工。
封裝函數AI_GENERATE_TEXT示例:
-- 定義封裝函數:
CREATE OR REPLACE FUNCTION Wrapper_AI_GENERATE_TEXT(prompt text, context text)
RETURNS TEXT AS
$$
DECLARE
result text := ' ';
BEGIN
SELECT PG_CATALOG.AI_GENERATE_TEXT ('<... use_your_endpoint ...>',
'<... use_your_token ...>',
prompt, context) INTO result;
IF result IS NOT NULL
AND result LIKE '%some_condition%' THEN
result := '<... your_expected_value ...> ';
END IF;
RETURN result;
END;
$$ LANGUAGE plpgsql;
-- 使用封裝函數,可以極大簡化使用方式:
SELECT Wrapper_AI_GENERATE_TEXT('浙江的省會在哪里?', null) AS 答復;
---------------------------
答復 | 浙江省的省會是杭州市。應用案例
對消費者在購物網站中發表的商品使用評價信息進行總結,并判斷其內容是趨于正面或負面的反饋。
執行如下語句,創建一張名為feedback_collect的表,其中存儲了消費者對于所購買商品的評價信息。
-- 創建表。
CREATE TABLE feedback_collect
(
id int not null,
name varchar(10),
age int,
feedback text,
AI_evaluation text
)
distributed by (id);
-- 插入客戶信息、以及對商品的‘評價信息’。
INSERT INTO feedback_collect VALUES(1, '張三', 38, '蘋果15手機外觀精美,輕薄便攜,功能強大。其擁有獨特的顏色和材質,同時屏幕清晰,操作流暢。拍照效果優秀,支持長焦功能,能夠滿足用戶的多種需求。此外,該手機還采用USB-C接口,支持快速充電和數據傳輸。總的來說,蘋果15是一款易于使用的手機,具有很高的性價比');
INSERT INTO feedback_collect VALUES(2, '李四', 30, 'Thinkpad P系列筆記本電腦外觀時尚,輕薄便攜,功能強大。它采用了高清晰度屏幕,操作流暢,鍵盤舒適,性能卓越。它支持多種連接方式,包括USB、HDMI和Thunderbolt等,同時也支持快速充電和數據傳輸。Thinkpad P系列筆記本電腦易于使用,具有很高的性價比');
INSERT INTO feedback_collect VALUES(3, '王五', 40, '這款手機貼膜真是太糟糕了!首先,它的質量很差,使用起來非常不順暢。其次,它的粘性很弱,沒過幾天就失去了粘性,無法保護手機屏幕。最重要的是,它還會影響我的使用體驗,讓我非常不滿意。我強烈建議大家不要購買這款貼膜,以免浪費時間和金錢');
INSERT INTO feedback_collect VALUES(4, '孫六', 45, '這款電動牙刷真是太差勁了!首先,它的電池壽命非常短,每次充電只能使用一兩天。其次,它的清潔效果也不如預期,牙齒上還是殘留了很多細菌。最重要的是,它的質量也很差,經常出現卡頓和故障。我非常失望,建議大家在購買之前一定要仔細考慮。');場景一:根據商品評價的內容,自動判斷其為正面反饋還是負面反饋,并把判斷結果存放回
feedback_collect表中。-- 首先查詢列AI_evaluation,可以看到目前尚無評價結果返回。 SELECT AI_evaluation FROM feedback_collect; -- 自動判斷:商品評價是正面/負面反饋,并保存于feedback_collect表中。 UPDATE feedback_collect SET AI_evaluation = PG_CATALOG.AI_GENERATE_TEXT('http://1648821****.vpc.cn-shanghai.pai-eas.aliyuncs.com/api/predict/test_pg', 'OGZiOGVkNTcwNTRiNzA0ODM1MGY0MTZhZGIwNT****', '判斷“'|| feedback ||'”的內容,是正面還是負面的。', '{ "history" : [ ["這臺相機的拍照效果不好,電池續航差!", "負面評價。"], ["這臺冰箱,節能、環保、噪音小。", "正面評價。"] ] }'); -- 再次查詢列AI_evaluation,可以看到如下信息。 SELECT AI_evaluation FROM feedback_collect; ai_evaluation ------------------------ 這段評價屬于負面評價。 負面評價。 正面評價。 正面評價。 (4 rows)場景二:選出負面反饋的用戶商品評價進行總結,并顯示輸出。
-- 對負面評價的內容,進行總結并返回。 SELECT feedback AS 原評價, AI_evaluation 原評價推理, PG_CATALOG.AI_GENERATE_TEXT('http://1648821****.vpc.cn-shanghai.pai-eas.aliyuncs.com/api/predict/test_pg', 'OGZiOGVkNTcwNTRiNzA0ODM1MGY0MTZhZGIwNT****', '對“'|| feedback ||'”的內容,進行總結。字數在30左右。', NULL) AS 總結 FROM feedback_collect WHERE AI_evaluation LIKE '%負面%'; -- 產生的結果如下。 -[ RECORD 1 ]------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ 原評價 | 這款手機貼膜真是太糟糕了!首先,它的質量很差,使用起來非常不順暢。其次,它的粘性很弱,沒過幾天就失去了粘性,無法保護手機屏幕。最重要的是,它還會影響我的使用體驗,讓我非常不滿意。我強烈建議大家不要購買這款貼膜,以免浪費時間和金錢 原評價推理 | 這段評價屬于負面評價。 總結 | 該款手機貼膜質量差、粘性弱且影響使用體驗,不建議購買。 -[ RECORD 2 ]------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ 原評價 | 這款電動牙刷真是太差勁了!首先,它的電池壽命非常短,每次充電只能使用一兩天。其次,它的清潔效果也不如預期,牙齒上還是殘留了很多細菌。最重要的是,它的質量也很差,經常出現卡頓和故障。我非常失望,建議大家在購買之前一定要仔細考慮。 原評價推理 | 負面評價。 總結 | 該電動牙刷的電池壽命短、清潔效果差、質量差,建議購買前仔細考慮。
場景一和場景二的推論結果僅作為參考示例。使用不同的大語言模型服務(如通義千問、ChatGLM等),所得到的推論結果會有差異。即使確定大語言模型后,將同一條SQL執行多次,所得到的推論結果內容,也會略有不同。
常見問題及解決方案
出錯信息提示
出現錯誤提示:
AI_GENERATE_TEXT error: HTTP request service failure或AI_GENERATE_TEXT error: Incorrect endpoint URL is specified。檢查在調用函數
PG_CATALOG.AI_GENERATE_TEXT時,參數input_endpoint是否填寫正確,一定要填寫在VPC下的地址。Endpoint獲取方式,請參見PG_CATALOG.AI_GENERATE_TEXT(...)函數介紹。出現錯誤提示:
AI_GENERATE_TEXT error: Incorrect endpoint URL is specified。檢查在調用函數
PG_CATALOG.AI_GENERATE_TEXT時,參數input_token是否填寫正確。Token獲取方式,請參見PG_CATALOG.AI_GENERATE_TEXT(...)函數介紹。出現錯誤提示:
AI_GENERATE_TEXT error: Invalid JSON syntax against the 4th parameter within UDF。請檢查在調用函數
PG_CATALOG.AI_GENERATE_TEXT時,參數input_additional_parms是否填寫正確。錯誤可能由如下原因引起:參數
input_additional_parms的JSON格式填寫不正確。參數
input_additional_parms使用了中文字符的逗號、單引號或雙引號,作為JSON格式的一部分,導致JSON 無法識別。
出現錯誤提示:
function AI_GENERATE_TEXT (unknown, unknown, unknown, unknown) does not exist。檢查AnalyticDB PostgreSQL版實例內核版本是否滿足要求。如何查看實例內核版本,請參見查看內核小版本。
調用函數
PG_CATALOG.AI_GENERATE_TEXT時,沒有指定Schema:PG_CATALOG,導致函數無法被系統識別。
調用AI_GENERATE_TEXT后,長時間沒有結果返回
當調用函數PG_CATALOG.AI_GENERATE_TEXT后,長時間沒有返回結果,可以從如下維度排查。
確保AnalyticDB PostgreSQL版實例的地域與LLM服務部署PAI-EAS所在的地域相同。
確保使用函數的
input_endpoint與input_token,與LLM服務的部署信息一致。詳情請參見參數。模型自身的性能問題。通常情況下,LLM服務處理一條請求的平均響應時間,在2~3秒(s)鐘左右。
說明該值僅作為參考。因為響應時間,與需要被分析內容的長度、生成推理內容的長度、不同模型自身的處理性能、部署模型的實例硬件規格、模型部署的實例個數,都有關系。
例如,使用
SELECT pg_catalog.ai_generate_text (...) where column >= ...語句,對文本內容進行推理。可以嘗試采用如下方法,提升文本推理的處理速度。增加LLM服務實例個數。
首先預估模型處理時間。
計算
SELECT COUNT(*) WHERE column >= ...需要處理數據的總量,假設得到數值為1000。抽樣若干條數據,統計LLM服務的處理時間。例如,SELECT pg_catalog.ai_generate_text (...) LIMIT 100統計處理100條請求的時間(可在應用程序內,執行該SELECT語句前后,記錄系統時間戳,以便統計執行時長)。基于該統計時間,乘以10可以大致估算整體的處理完成的時間。然后根據上述估算時間,增加部署LLM服務的實例個數。實例配置規格選擇建議,請參見附錄:LLM服務實例配置規格建議。
增加LLM服務實例個數的方法有以下幾種:
對于執行時間較長的SQL語句,合理設置如下參數,避免語句超時。示例如下:
SET idle_in_transaction_session_timeout =5h;設置連接5小時后超時(根據實際情況合理設置超時時間)。SET statement_timeout = 0;設置執行語句永不超時(酌情考慮)。
附錄:LLM服務實例配置規格建議
LLM服務的計算資源主要由GPU承擔。因此,如果對LLM服務處理請求時間有較高要求,可以選擇規格更高的GPU。
GPU核數的選擇:在保證相同核數的前提下,服務實例數越多,對LLM處理請求時間的提升會更明顯。
例如,同樣選擇4核的GPU,部署4個單核GPU的實例,對LLM處理請求性能的提升更明顯。并且部署4個單核GPU的實例,與部署1個4核GPU的實例,成本是相同的。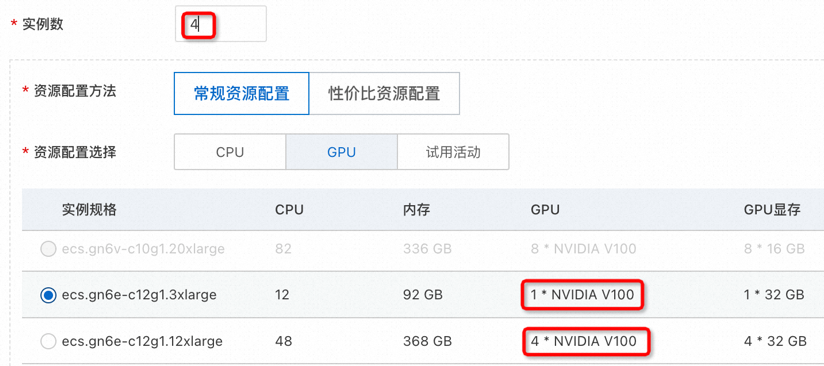
相關文檔
如果您想了解更多關于阿里云PAI模型在線服務(EAS)信息,請參見EAS模型服務概述。