分組聚合查詢優化
本文介紹如何在AnalyticDB for MySQL中對分組聚合查詢進行優化。
分組聚合流程
AnalyticDB for MySQL是分布式數據倉庫,其分組聚合查詢默認分為兩步:
完成數據的局部(PARTIAL)聚合。
局部聚合節點只需要占用少量內存,聚合過程為流式過程,數據不會堆積在局部聚合節點上。
局部聚合完成后,數據根據分組字段進行節點間的數據重分布,執行最終(FINAL)聚合。
局部聚合后的結果會通過網絡傳輸到下游Stage的節點(更多關于Stage的信息,請參見影響查詢性能的因素)。因為數據已經經過了局部聚合,所以需要網絡傳輸的數據較少,網絡壓力較小。數據重分布完成后,執行最終聚合,在最終聚合節點,需要把一個分組的值及其聚合狀態維護在內存中,直到所有數據處理完成,以確保某個特定的分組值沒有新的數據需要處理,所以最終聚合節點可能會占用較大的內存空間。
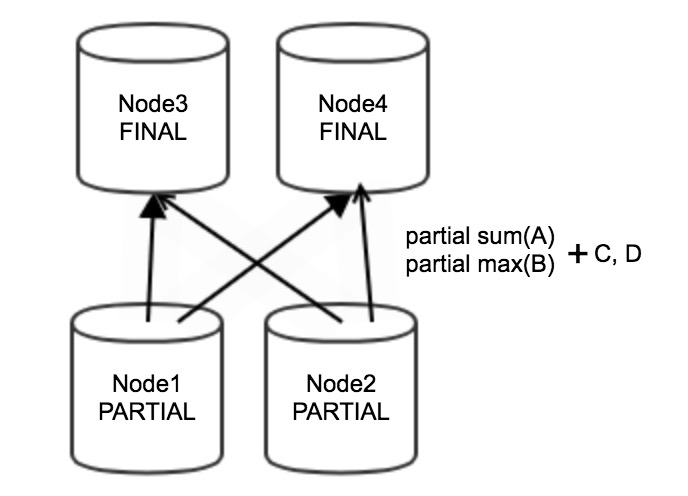
例如執行以下的SQL分組聚合語句。
SELECT sum(A), max(B) FROM tb1 GROUP BY C,D;上述語句在進行分組聚合時,數據會首先在上游Stage的Node1和Node2節點中執行局部聚合,局部聚合的結果是partial sum(A)、partial max(B)、C、D。局部聚合的結果會通過網絡傳輸到下游Stage的Node3和Node4節點中進行最終聚合。流程圖如下。
通過Hint優化分組聚合
適用場景
在大多數場景下,兩步聚合可以在內存和網絡資源之間實現較好的平衡,但在分組聚合的分組數較多(即GROUP BY字段的唯一值較多)等特殊場景下,兩步聚合不一定是最好的處理方法。
例如,在需要使用手機號碼或用戶ID進行分組的場景下,如果依舊使用典型的兩步聚合方式,那么在局部聚合階段,可以被聚合的數據較少,但是局部聚合流程依舊會執行(例如,計算分組的HASH值、去重以及執行聚合函數)。由于分組數多,局部聚合階段并沒有減少網絡傳輸的數據量,卻消耗了很多計算資源。
使用方法
為解決上述聚合度較低的分組聚合查詢問題,您可以在執行查詢時添加Hint
/*+ aggregation_path_type=single_agg*/來跳過局部聚合,直接進行最終聚合,來減少不必要的計算開銷。說明如果在查詢SQL中使用了
/*+ aggregation_path_type=single_agg*/Hint,那么該SQL中所有的分組聚合查詢都會使用這個特定的優化流程,因此最佳的方式是先分析原始執行計劃中的聚合算子的特點,并評估該Hint帶來的收益,最后決定是否使用該優化方案。優化說明
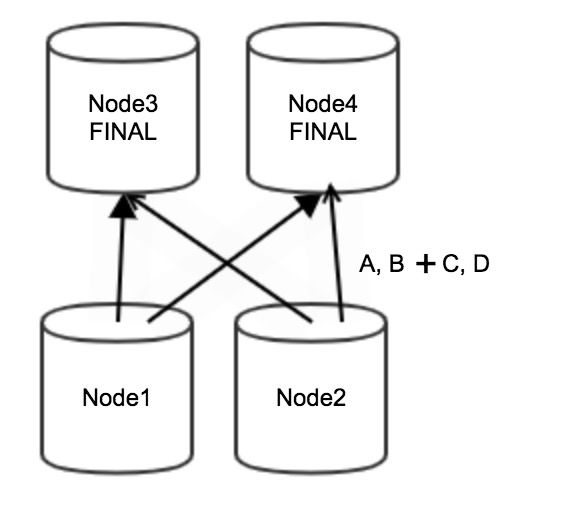
聚合度較低的情況下,上游Stage的Node1和Node2節點進行局部聚合并沒有減少網絡傳輸的數據量,卻消耗了很多計算資源。
優化后Node1和Node2節點不需要進行局部聚合,全部數據(即A、B、C、D)直接由下游Stage的Node3和Node4節點進行最終聚合,從而減少了計算量,流程圖如下。
 說明
說明該優化不一定能起到優化內存使用的目的,因為在聚合度較低的情況下,數據還是會大量地積攢在內存中進行去重和聚合以確保某個分組值的數據全部處理完成。