數(shù)據(jù)導(dǎo)入性能優(yōu)化
云原生數(shù)據(jù)倉(cāng)庫(kù) AnalyticDB MySQL 版提供的多種數(shù)據(jù)導(dǎo)入方法,滿足不同場(chǎng)景下的數(shù)據(jù)導(dǎo)入需求。然而數(shù)據(jù)導(dǎo)入性能依然受各種各樣的因素影響,如表的建模不合理導(dǎo)致長(zhǎng)尾、導(dǎo)入配置低無(wú)法有效利用資源等。本文介紹不同場(chǎng)景下的數(shù)據(jù)導(dǎo)入調(diào)優(yōu)方法。
通用外表導(dǎo)入數(shù)據(jù)調(diào)優(yōu)
檢查分布鍵
分布鍵決定著數(shù)據(jù)導(dǎo)入的一級(jí)分區(qū),每個(gè)表在導(dǎo)入時(shí)以一級(jí)分區(qū)為粒度并發(fā)導(dǎo)入。當(dāng)數(shù)據(jù)分布不均勻時(shí),導(dǎo)入數(shù)據(jù)較多的一級(jí)分區(qū)將成為長(zhǎng)尾節(jié)點(diǎn),影響整個(gè)導(dǎo)入任務(wù)的性能,因此要求導(dǎo)入時(shí)數(shù)據(jù)均勻分布。如何選擇分布鍵,請(qǐng)參見(jiàn)選擇分布鍵。
判斷分布鍵合理性:
導(dǎo)入前,根據(jù)導(dǎo)入數(shù)據(jù)所選分布鍵的業(yè)務(wù)意義判斷是否合理。以表Lineitem為例,當(dāng)選擇l_discount列為分布鍵,訂單折扣值區(qū)分度很低,僅有11個(gè)不同值,l_discount值相同的數(shù)據(jù)會(huì)分布到同一分區(qū),造成嚴(yán)重傾斜,導(dǎo)入會(huì)有長(zhǎng)尾,影響性能。選擇l_orderkey列則更為合適,訂單ID互不相同,數(shù)據(jù)分布相對(duì)較為均勻。
導(dǎo)入后,數(shù)據(jù)建模診斷中如有分布字段傾斜,則說(shuō)明選擇的分布鍵不均勻。如何查看分布鍵診斷信息,請(qǐng)參見(jiàn)存儲(chǔ)空間診斷。
檢查分區(qū)鍵
INSERT OVERWRITE SELECT導(dǎo)入數(shù)據(jù)的基本特性為分區(qū)覆蓋,即導(dǎo)入的二級(jí)分區(qū)會(huì)覆蓋原表的同名二級(jí)分區(qū)。每個(gè)一級(jí)分區(qū)內(nèi)的數(shù)據(jù)會(huì)再按二級(jí)分區(qū)定義導(dǎo)入各個(gè)二級(jí)分區(qū)。導(dǎo)入時(shí)需要避免一次性導(dǎo)入過(guò)多二級(jí)分區(qū),多個(gè)二級(jí)分區(qū)同時(shí)導(dǎo)入可能引入外排序過(guò)程,影響導(dǎo)入性能。如何選擇分區(qū)鍵,請(qǐng)參見(jiàn)選擇分區(qū)鍵。
判斷分區(qū)鍵合理性:
導(dǎo)入前,根據(jù)業(yè)務(wù)數(shù)據(jù)需求及數(shù)據(jù)分布判斷分區(qū)鍵是否合理。如Lineitem表按l_shipdate列做二級(jí)分區(qū),數(shù)據(jù)范圍橫跨7年,按年做分區(qū)有7個(gè)分區(qū),按日做分區(qū)有2000多個(gè)分區(qū),單分區(qū)約3000萬(wàn)條記錄,選擇按月或者按年做分區(qū)則更合適。
導(dǎo)入后,數(shù)據(jù)建模診斷中如有不合理的二級(jí)分區(qū),則選擇的分區(qū)鍵不合適。如何查看分區(qū)鍵診斷信息,請(qǐng)參見(jiàn)分區(qū)表診斷。
檢查索引
AnalyticDB for MySQL建表時(shí)默認(rèn)全列索引,而構(gòu)建寬表的全列索引會(huì)消耗部分資源。導(dǎo)入數(shù)據(jù)到寬表時(shí),建議使用主鍵索引。主鍵索引用于去重,主鍵列數(shù)過(guò)多影響去重性能。如何選擇主鍵索引,請(qǐng)參見(jiàn)選擇主鍵。
判斷索引合理性:
離線導(dǎo)入場(chǎng)景通常已經(jīng)通過(guò)離線計(jì)算進(jìn)行去重,無(wú)需指定主鍵索引。
在頁(yè)簽,查看表數(shù)據(jù)量、索引數(shù)據(jù)量和主鍵索引數(shù)據(jù)量。當(dāng)索引數(shù)據(jù)量超過(guò)表數(shù)據(jù)量時(shí),需要檢查表中是否有較長(zhǎng)的字符串列,這種索引列不僅構(gòu)建耗時(shí),還占用存儲(chǔ)空間,可以刪除索引,請(qǐng)參見(jiàn)ALTER TABLE。
說(shuō)明主鍵索引無(wú)法刪除。需要重建表。
增加Hint加速導(dǎo)入
在導(dǎo)入任務(wù)前增加Hint(direct_batch_load=true)可以加速導(dǎo)入任務(wù)。
該Hint僅數(shù)倉(cāng)版彈性模式集群3.1.5版本支持,若使用后導(dǎo)入性能無(wú)明顯提升,請(qǐng)提交工單。
示例如下:
SUBMIT JOB /*+ direct_batch_load=true*/INSERT OVERWRITE adb_table
SELECT * FROM adb_external_table;使用彈性導(dǎo)入功能加速導(dǎo)入
僅內(nèi)核版本3.1.10.0及以上的集群支持使用彈性導(dǎo)入功能。
已創(chuàng)建Job型資源組的企業(yè)版、基礎(chǔ)版及湖倉(cāng)版集群支持使用彈性導(dǎo)入功能。
彈性導(dǎo)入僅支持導(dǎo)入MaxCompute數(shù)據(jù)和以CSV、Parquet、ORC格式存儲(chǔ)的OSS數(shù)據(jù)。
使用彈性導(dǎo)入功能加速導(dǎo)入時(shí),需確保Job型資源組中可用資源充足,避免資源不足導(dǎo)致任務(wù)長(zhǎng)時(shí)間等待、耗時(shí)長(zhǎng)、任務(wù)失敗等問(wèn)題。
彈性導(dǎo)入支持同時(shí)運(yùn)行多個(gè)彈性導(dǎo)入任務(wù),也支持通過(guò)增大單個(gè)彈性導(dǎo)入任務(wù)使用的資源加速導(dǎo)入。更多信息,請(qǐng)參見(jiàn)數(shù)據(jù)導(dǎo)入方式介紹。
示例如下:
/*+ elastic_load=true, elastic_load_configs=[adb.load.resource.group.name=resource_group]*/
submit job insert overwrite adb_table select * from adb_external_table;參數(shù)說(shuō)明,請(qǐng)參見(jiàn)Hint參數(shù)說(shuō)明。
通過(guò)DataWorks導(dǎo)入數(shù)據(jù)調(diào)優(yōu)
優(yōu)化任務(wù)配置
優(yōu)化批量插入條數(shù)
表示單次導(dǎo)入的批大小,默認(rèn)為2048,一般不建議修改。
如果單條數(shù)據(jù)量過(guò)大達(dá)到數(shù)百KB,如高達(dá)512 KB,則建議修改此配置為16,保證單次導(dǎo)入量不超過(guò)8 MB,防止占用過(guò)多前端節(jié)點(diǎn)內(nèi)存。
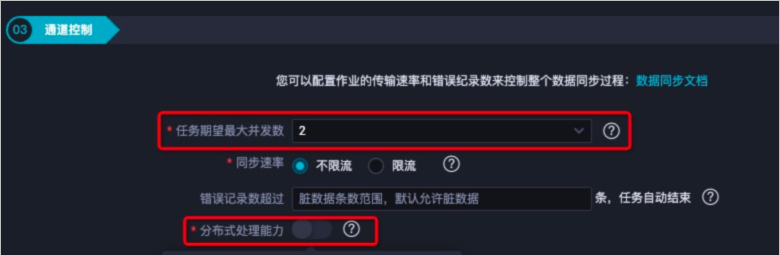
優(yōu)化通道控制
數(shù)據(jù)同步性能與任務(wù)期望最大并發(fā)數(shù)配置項(xiàng)大小成正比,建議盡可能增加任務(wù)期望最大并發(fā)數(shù)。
重要任務(wù)期望最大并發(fā)數(shù)越高,占用DataWorks資源會(huì)越多,請(qǐng)合理選擇。
建議打開(kāi)分布式處理能力,以取得更好的同步性能。
常見(jiàn)問(wèn)題及解決方法
當(dāng)客戶端導(dǎo)入壓力不足時(shí),會(huì)導(dǎo)致集群CPU使用率、磁盤(pán)IO使用率及寫(xiě)入響應(yīng)時(shí)間處于較低水位。數(shù)據(jù)庫(kù)服務(wù)器端雖然能夠及時(shí)消費(fèi)客戶端發(fā)送的數(shù)據(jù),但由于總發(fā)送量較小,導(dǎo)致寫(xiě)入TPS不滿足預(yù)期。
解決方法:調(diào)大單次導(dǎo)入的批量插入條數(shù)及增加任務(wù)期望最大并發(fā)數(shù),數(shù)據(jù)導(dǎo)入性能會(huì)隨著導(dǎo)入壓力的增加而線性增加。
當(dāng)導(dǎo)入的目標(biāo)表存在數(shù)據(jù)傾斜時(shí),集群部分節(jié)點(diǎn)負(fù)載過(guò)高,影響導(dǎo)入性能。此時(shí),集群CPU使用率、磁盤(pán)IO使用率處于較低水位,但寫(xiě)入響應(yīng)時(shí)間較高,同時(shí)您可以在頁(yè)面的傾斜診斷表中發(fā)現(xiàn)目標(biāo)表。
解決方法:重新設(shè)計(jì)表結(jié)構(gòu)后再導(dǎo)入數(shù)據(jù),詳情請(qǐng)參見(jiàn)表結(jié)構(gòu)設(shè)計(jì)。
通過(guò)JDBC使用程序?qū)霐?shù)據(jù)調(diào)優(yōu)
客戶端優(yōu)化
應(yīng)用端攢批,多條批量導(dǎo)入
在通過(guò)JDBC使用程序?qū)霐?shù)據(jù)過(guò)程中,為減少網(wǎng)絡(luò)和鏈路上的開(kāi)銷,建議攢批導(dǎo)入。無(wú)特殊要求,請(qǐng)避免單條導(dǎo)入。
批量導(dǎo)入條數(shù)建議為2048條。如果單條數(shù)據(jù)量過(guò)大達(dá)到數(shù)百KB,建議攢批數(shù)據(jù)大小不超過(guò)8 MB,可通過(guò)8 MB/單條數(shù)據(jù)量得到攢批條數(shù)。否則單批過(guò)大容易占用過(guò)多前端節(jié)點(diǎn)內(nèi)存,影響導(dǎo)入性能。
應(yīng)用端并發(fā)配置
應(yīng)用端導(dǎo)入數(shù)據(jù)時(shí),建議多個(gè)并發(fā)同時(shí)導(dǎo)入數(shù)據(jù)。單進(jìn)程無(wú)法完全利用系統(tǒng)資源,且一般客戶端需要處理數(shù)據(jù)、攢批等操作,難以跟上數(shù)據(jù)庫(kù)的導(dǎo)入速度,通過(guò)多并發(fā)導(dǎo)入可以加快導(dǎo)入速度。
導(dǎo)入并發(fā)受攢批、數(shù)據(jù)源、客戶端機(jī)器負(fù)載等影響,沒(méi)有最合適的數(shù)值,建議通過(guò)測(cè)試逐步計(jì)算合適的并發(fā)能力。如導(dǎo)入不達(dá)預(yù)期,請(qǐng)翻倍加大并發(fā),導(dǎo)入速度下降再逐步降低并發(fā),尋找最合適的并發(fā)數(shù)。
常見(jiàn)問(wèn)題及解決方法
當(dāng)通過(guò)程序?qū)霐?shù)據(jù)到AnalyticDB for MySQL性能不佳時(shí),首先排查客戶端性能是否存在瓶頸。
保證數(shù)據(jù)源的數(shù)據(jù)生產(chǎn)速度足夠大,如果數(shù)據(jù)源來(lái)自其他系統(tǒng)或文件,排查客戶端是否有輸出瓶頸。
保證數(shù)據(jù)處理速度,排查數(shù)據(jù)生產(chǎn)消費(fèi)是否同步,保證有足夠的數(shù)據(jù)等待導(dǎo)入AnalyticDB for MySQL。
保證客戶端機(jī)器負(fù)載,檢查CPU使用率或磁盤(pán)IO使用率等系統(tǒng)資源是否充足。