向量檢索
AnalyticDB for MySQL的向量檢索功能可以幫助您實現非結構化數據的近似檢索。本文主要介紹向量檢索功能以及如何創建并使用向量索引。
前提條件
集群的內核版本需為3.1.4.0及以上版本。
內核版本為3.1.5.16、3.1.6.8、3.1.8.6及以上版本的集群向量索引功能相對穩定。
若您的集群不是上述列舉的穩定版本,建議您先將參數CSTORE_PROJECT_PUSH_DOWN和CSTORE_PPD_TOP_N_ENABLE設置為false,再使用向量索引功能。
如何查看集群內核版本,請參見如何查看實例版本信息。如需升級內核版本,請聯系技術支持。
背景信息
功能介紹
您可以通過AI算法提取非結構化數據的特征進行數據編碼,形成一個特征向量,將特征向量存儲在AnalyticDB for MySQL中。使用特征向量標識非結構化數據,向量間的距離用于衡量非結構化數據之間的相似度。AnalyticDB for MySQL集群提供高效的向量檢索功能,可應用于圖片檢索、聲紋匹配、人臉識別、文本檢索等場景中。
產品架構
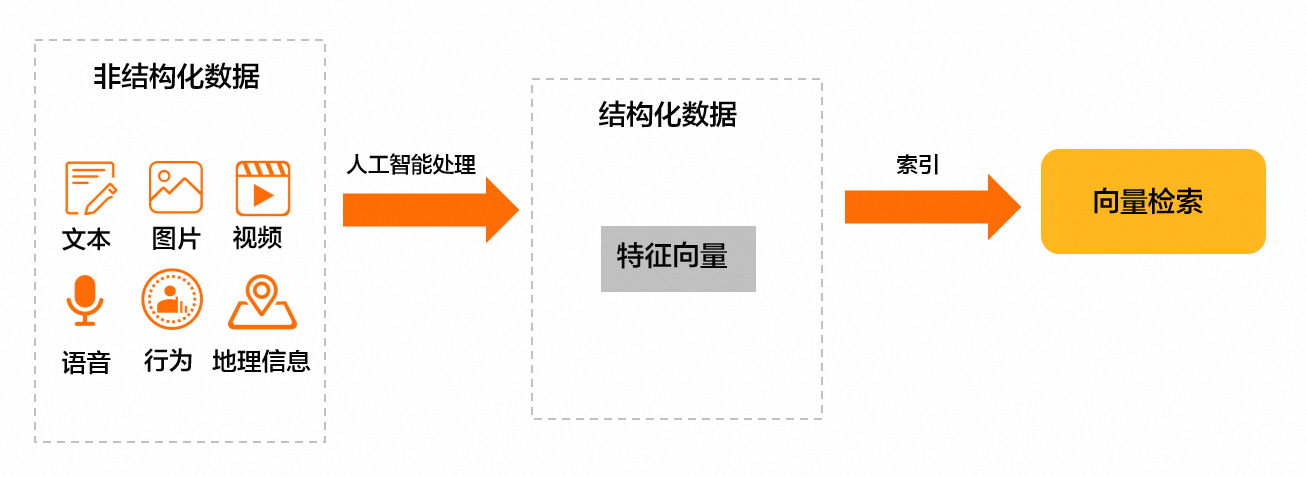
產品優勢
向量數據的高維度、高性能和高召回率。
以人臉512維向量為例,AnalyticDB for MySQL向量檢索提供百億向量100 QPS、50毫秒響應時間約束下99%的數據召回率和兩億向量1000 QPS、1秒響應時間約束下99%的數據召回率。
結構化和非結構數據的融合查詢
支持KNN和RNN融合查詢,例如:比較一批向量與另外一批向量的相似度。
實時更新
支持高并發的實時寫入和實時更新,數據寫入后即可查詢。
實時檢索
MPP查詢架構提供毫秒級實時檢索性能,提升檢索效率。
開箱即用
支持標準的SQL語句,簡化開發流程,不需要額外安裝其他復雜的配置。
基本概念
特征向量
向量是一種將實體和應用代數化的表示。向量將實體間的關系抽象成向量空間中的距離,距離的遠近代表相似程度。例如:身高、年齡、性別、地域等。在AnalyticDB for MySQL中,特征向量的數據類型為數組,僅支持固定長度數組。
向量檢索
在特征向量數據集合中進行快速搜索和匹配的方法。
向量索引
特定類型的索引。
距離計算
特定類型的自定義函數,每個距離計算公式對應一個自定義函數。例如:L2_DISTANCE。
KNN
KNN(K-Nearest Neighbor)算法用于查找特征向量數據集合中離查詢點最近的 K 個點。
RNN
RNN(Radius Nearest Neighbor)算法用于查找特征向量數據集合中查詢點在某半徑范圍內的所有點。
創建向量索引
語法
您可以在創建表時同步創建向量索引。定義為:
ANN INDEX [index_name] (column_name)] [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]參數說明
ANN INDEX:向量索引關鍵字。
index_name:索引名。索引的命名規則,請參見命名約束。
column_name:向量列的名稱。列名的命名規則,請參見命名約束。 僅支持
array <float>、array <byte>、array <smallint>三種數據類型。algorithm:向量距離計算公式使用的算法,取值僅支持:
HNSW_PQ。distancemeasure:向量距離計算公式,取值僅支持:
SquaredL2。SquaredL2的計算公式為:(x1-y1)2+(x2-y2)2+…...(xn-yn)2。
示例
本示例創建表vector,表定義了兩個向量列float_feature和short_feature,其中,float_feature的類型為arrary<float>,維度為4,short_feature類型為arrary<smallint>,維度也為4,對這兩個列分別創建向量索引。
CREATE TABLE vector (
xid BIGINT NOT NULL,
cid BIGINT NOT NULL,
uid VARCHAR NOT NULL,
vid VARCHAR NOT NULL,
wid VARCHAR NOT NULL,
float_feature ARRAY < FLOAT >(4),
short_feature ARRAY < SMALLINT >(4),
ANN INDEX idx_short_feature(short_feature),
ANN INDEX idx_float_feature(float_feature),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);增加向量索引
語法
您可以在創建表后增加向量索引。定義為:
ALTER TABLE table_name ADD ANN INDEX [index_name] (column_name) [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]示例
假設已有表vector,建表語句如下。
CREATE TABLE vector (
xid BIGINT not null,
cid BIGINT not null,
uid VARCHAR not null,
vid VARCHAR not null,
wid VARCHAR not null,
float_feature array < FLOAT >(4),
short_feature array < SMALLINT >(4),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);為float_feature和short_feature創建向量索引,示例如下。
ALTER TABLE vector ADD ANN INDEX idx_float_feature(float_feature);
ALTER TABLE vector ADD ANN INDEX idx_short_feature(short_feature);查詢向量數據
您可以在查詢語句中加入距離計算函數,將實體關系抽象成向量空間的距離。例如L2_DISTANCE。
示例
插入數據
已建好表vector后,在表中插入數據。
INSERT INTO vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (1,2,'A','B','C','[1,1,1,1]','[1.2,1.5,2,3.0]');
INSERT INTO vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (2,1,'e','v','f','[2,2,2,2]','[1.5,1.15,2.2,2.7]');
INSERT INTO vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (0,6,'d','f','g','[3,3,3,3]','[0.2,1.6,5,3.7]');
INSERT INTO vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','b','h','[4,4,4,4]','[1.0,4.15,6,2.9]');
INSERT INTO vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (8,5,'Sj','Hb','Dh','[5,5,5,5]','[1.3,4.5,6.9,5.2]');
INSERT INTO vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'x','g','h','[3,4,4,4]','[1.0,4.15,6,2.9]');
INSERT INTO vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','r','k','[6,6,4,4]','[1.0,4.15,6,2.9]');
INSERT INTO vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'s','i','q','[2,2,4,4]','[1.0,4.15,6,2.9]');查詢數據
查詢short_feature與向量
'[1,1,1,1]'距離最近的3條記錄,按距離排序:SELECT xid, l2_distance(short_feature, '[1,1,1,1]') AS dis FROM vector ORDER BY 2 LIMIT 3;返回結果:
+-------+--------------+ | xid | dis | +-------+--------------+ | 1 | 0.0 | +-------+--------------+ | 2 | 4.0 | +-------+--------------+ | 0 | 16.0 | +-------+--------------+查詢xid為5且cid為4,short_feature與向量
'[1,1,1,1]'距離最近的4條記錄,按距離排序:SELECT uid, l2_distance(short_feature, '[1,1,1,1]') AS dis FROM vector WHERE xid = 5 AND cid = 4 ORDER BY 2 LIMIT 4;返回結果:
+-------+--------------+ | uid | dis | +-------+--------------+ | s | 20.0 | +-------+--------------+ | x | 31.0 | +-------+--------------+ | j | 36.0 | +-------+--------------+ | j | 68.0 | +-------+--------------+查詢short_feature與向量
'[1,1,1,1]'距離最近的3條記錄,按距離排序,且距離不能超過50:SELECT uid, l2_distance(short_feature, '[1,1,1,1]') AS dis FROM vector WHERE l2_distance(short_feature, '[1,1,1,1]') < 50.0 AND xid = 5 ORDER BY 2 LIMIT 3;返回結果:
+-------+---------------+ | uid | dis | +-------+---------------+ | s | 20.0 | +-------+---------------+ | x | 31.0 | +-------+---------------+ | j | 36.0 | +-------+---------------+