本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
本文介紹了Alibaba Cloud Linux 3系統中使用GPU進行加速的容器啟動后,容器內無法使用GPU的原因及解決方案。
問題現象
在Alibaba Cloud Linux 3系統中,當systemd版本低于systemd-239-68.0.2.al8.1時,執行systemctl daemon-reload命令后容器無法訪問GPU。
在容器內執行
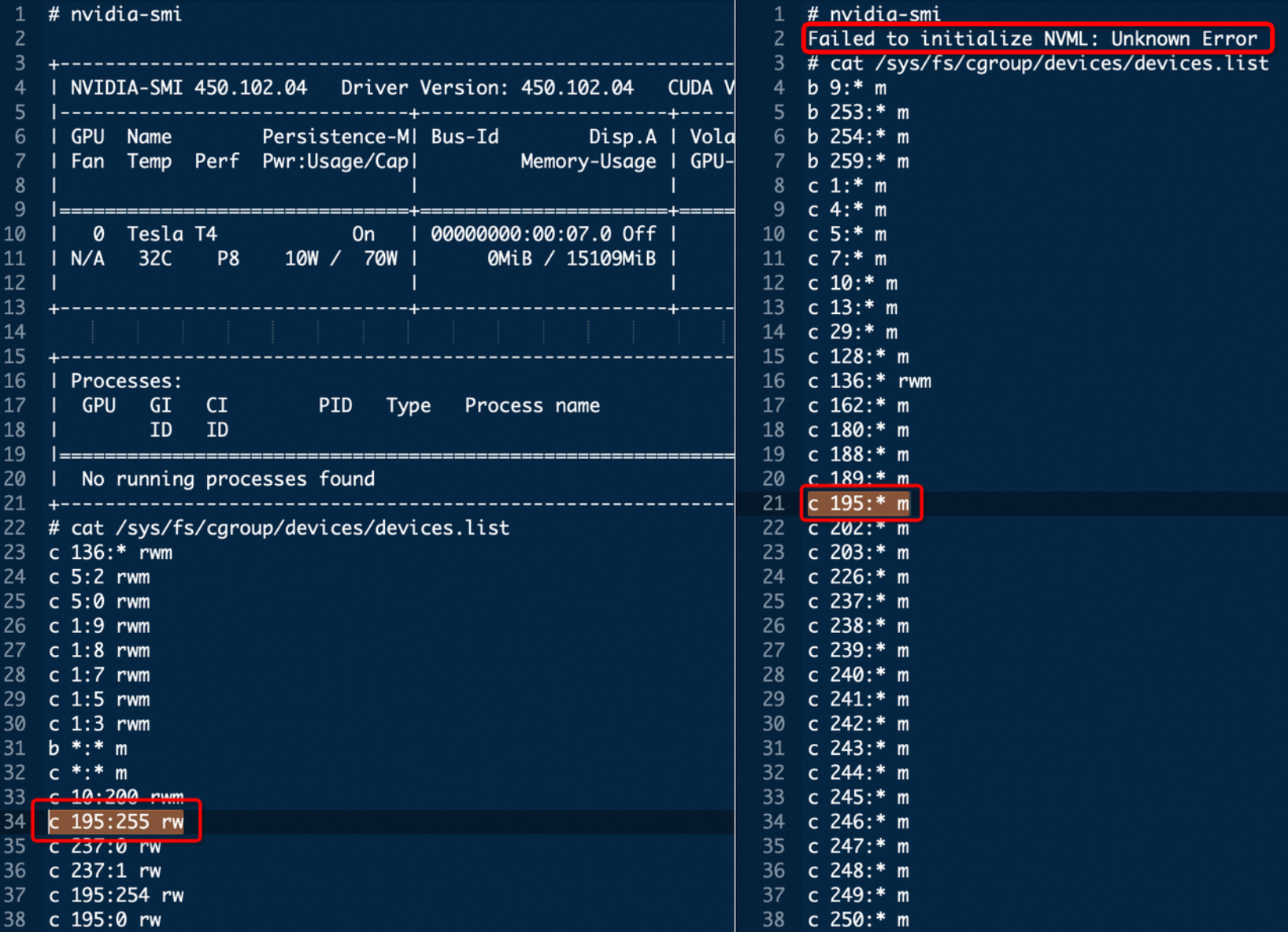
nvidia-smi無法查看到GPU信息。devices.list發生了變化,例如GPU 0對應的權限變為195:* m。
具體現象如下圖所示(左圖表示容器可正常訪問GPU,右圖表示容器無法訪問GPU)。
問題原因
在/dev/char/目錄下以設備序號命名的設備節點(例如/dev/char/195:255)與真實的NVIDIA GPU設備節點(例如/dev/nvidiactl)之間不存在軟連接。但runc(運行容器的引擎)自行實現了這兩者之間的關系轉換,在容器啟動時,runc會為該容器和所關聯的GPU設置正確的device cgroup(設備控制組)。但是,runc提供給systemd的位于/dev/char/目錄下,以設備序號命名的設備節點(例如/dev/char/195:255)的cgroup(Control Group)配置信息并不存在。
執行systemctl daemon-reload命令會將當前所有由systemd管理的狀態進行序列化,然后通過讀取磁盤上的配置文件和反序列化應用新的狀態的過程中,systemd會根據自己所記錄的狀態重新應用所有的cgroup配置。但是,在不存在軟連接關系的情況下,由于systemd需要設置的/dev/char/目錄下以設備序號命名的設備節點(例如/dev/char/195:255)并不存在,導致systemd無法設置該cgroup,從而引發容器中無法使用GPU的問題。

解決方案
阿里云在systemd-239-78.0.4版本中新增了一個默認打開的選項FullDelegationDeviceCGroup,在服務配置Delegate=yes的情況下,默認不重新應用device cgroup(設備控制組)。您可以將systemd升級到最新版本以解決該問題。
在ECS實例中升級
systemd至最新版本。sudo yum upgrade systemd輸入
y確定升級。重啟ECS實例,使配置生效。
警告重啟實例將導致您的實例暫停運行,這可能引發業務中斷和數據丟失。因此,建議您在執行此操作之前備份關鍵數據,并選擇在非業務高峰期進行。
sudo reboot確認
systemd版本為systemd-239-78.0.4或以上版本。rpm -qa systemd在容器內執行
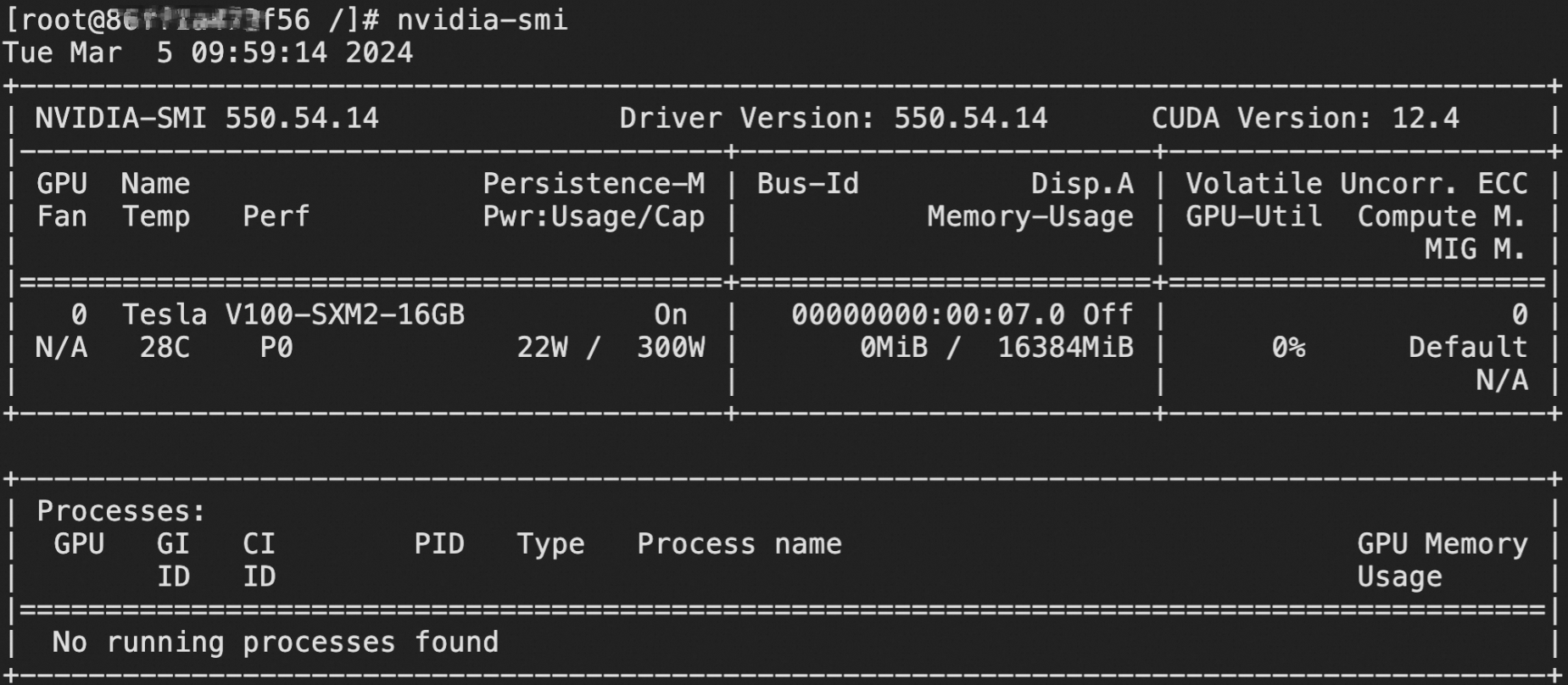
nvidia-smi查看GPU信息。nvidia-smi結果如下圖所示,表明可以正常訪問GPU。