PAI-Rec選型主要包括如下兩個部分:
一、服務選型
為便于開發者更加便捷地使用服務,將為企業開發者提供3種不同的推薦算法服務。
序號 | 服務類型 | 說明 | 目錄價 |
1 | 標準版服務 | 推薦引擎配置 服務發布管理 指標注冊與自定義、實驗報表 AB實驗平臺、推薦數據排查工具 一致性檢查工具 | 5000元/月 |
2 | 高級版服務 | 較標準版新增加: 數據智能診斷 推薦算法定制(配置產出召回、特征工程、排序代碼,一鍵部署,新物品冷啟動等功能) | 8000元/月 |
3 | 增值功能 | 定向運營(流量調控、物品封禁和置頂、定坑) | 1000元/月 |
若開發者使用的算法服務為行業標準配置、或者自行完成算法組裝,將無需支付額外的費用。 若需要根據場景定制,設計鏈路配置,模型選型,按照效果交付調優等,則需進行商務洽談后支付定制人天費用。
初次接入服務,建議優先選擇高級版服務接入,因為高級版本中包含數據診斷和推薦算法定制功能。通過數據診斷可以分析用戶特征、物品特征中特征的有效性,分析用戶行為表是否正確,并且決定推薦算法定制中的特征和排序模型等參數。推薦算法定制可以幫助用戶生成相關代碼,快速產出召回和排序相關的數據和模型,并一鍵部署。
二、資源選型
構建完整的推薦系統,需要一些劃分相對獨立的數據模塊、算法模塊、在線鏈路模塊等,需要按照開發習慣、現有業務系統的數據架構,選擇合適的資源拼裝選型。
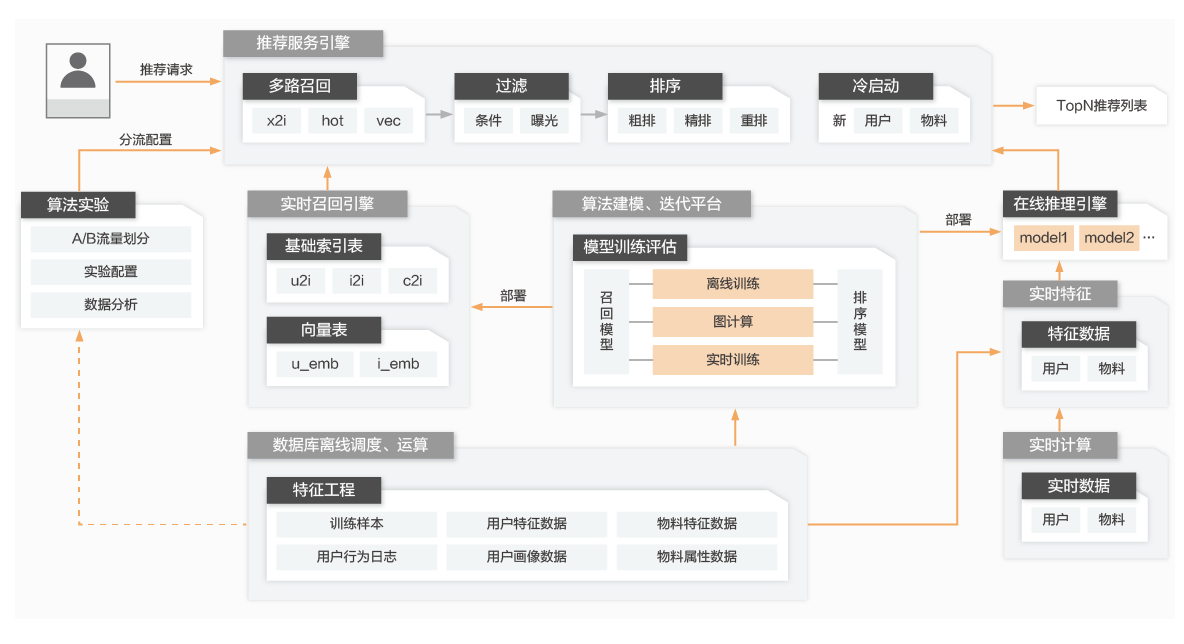 基于大數據開發實踐,我們建議的選型為:
基于大數據開發實踐,我們建議的選型為:
序號 | 模塊/用途 | 云服務 |
1 | 建模、數據清洗、任務調度等 | 機器學習PAI、大數據開發治理平臺DataWorks、 云原生大數據計算服務MaxCompute |
2 | 模型存儲 | 對象存儲OSS |
3 | 實時特征存儲引擎 向量召回引擎 | Hologres 圖計算GraphCompute |
4 | 在線預測引擎 | 在線預測服務(PAI-EAS) |
此外,為保證服務的便捷運維,數據便捷回流,以及后續代碼級更加靈活的開發,我們建議開通如下服務:
序號 | 模塊/用途 | 云服務 |
1 | 數據總線DataHub | 用于實時日志回流,持續更新用戶行為,用于模型訓練 |
2 | 日志服務SLS | 用戶請求日志將推送至SLS服務,可前往SLS服務管理運維 |
3 | 容器鏡像服務 |
|
選型方案建議
基于客戶不同的業務現狀和需求可開通不同的資源組合,不同的算法組合也影響需要的資源。
此處的DAU規模僅為預估,不是一個嚴格的分界線,主要是基于提高推薦效果是否能帶來足夠的業務價值,以覆蓋推薦系統的成本。
以小于5萬的方案為基準,下面的方案都是在上一方案基礎上的變化。
DAU規模 | 召回模型建議 | 排序模型建議 | 用戶特征存儲建議 |
DAU小于5萬 | 不使用向量召回模型,可不部署向量召回引擎 | 使用相對簡單的單目標多塔模型,推理速度快效果比較好,同時節約PAI-EAS的資源。 使用MaxCompute預付費資源,做特征工程、樣本處理、深度學習模型訓練 | 通過Flink寫入到Redis中。 |
DAU大于5萬 | 可以增加向量召回。所有特征存儲、向量查詢都使用Hologres產品。 | 使用多目標排序模型。 | 當用戶特征快速變化的情況,可考慮Graphcompute |
DAU大于20萬 | 用戶向量的實時推理 物品冷啟動算法,如協同度量學習算法 | 建議使用增量訓練節約訓練成本。 建議增加物品實時特征。 | 可以考慮Graphcompute |
DAU大于50萬 | 如果經常有活動影響推薦系統的效果,可以考慮增加在線學習的方案。 即通過Flink實時拼接樣本,在線學習模型并且每天多次更新線上的模型。 | 可考慮預付費的MaxCompute資源。 | |
當新物品較多:
建議使用物品冷啟動算法,讓新物品分發更加合理。
當需要調控指定物品、指定類目的流量:
建議使用流量調控的算法,按照物品、物品集合、物品類目來調整曝光流量數量、曝光占比。
其他建議:
用戶特征數量多:可以嘗試把用戶特征存儲在OTS(表格存儲)。
PAI-EAS:注意在業務高峰期配置定時擴容,同時配置自動縮容保證到業務低峰期收縮資源。
PAI-EAS打分服務:可考慮預付費資源和彈性擴縮容資源相結合。
用戶有社交關系:建議使用GraphCompute管理用戶之間的關注、好友關系。有社交關系的推薦場景建議使用GraphSage等圖算法。