當部署一個云原生AI集群之后,集群管理員需要對集群資源進行劃分,并從多個維度查看集群資源的使用情況,以便及時做出調整,使集群達到最佳的利用率。本文介紹云原生AI集群的基本運維操作,包括安裝AI套件、查看資源大盤、管理用戶和配額。
背景信息
當部署一個云原生AI集群之后,集群管理員需要對集群資源進行劃分,管理多個項目組,并可以多個維度查看集群資源的使用情況,以便及時做出調整,使集群達到最佳的利用率。
當集群中有多個用戶時,為了保障用戶有足夠的資源使用,管理員會將集群的資源固定分配給不同的用戶。傳統的方法是通過Kubernetes原生的ResourceQuota方式進行固定資源的分配。但由于小組之間資源忙閑不一,為了集群整體利用率達到最高,需要在確保用戶的資源分配的基礎上通過資源共享的方式來提升整體資源的利用率。
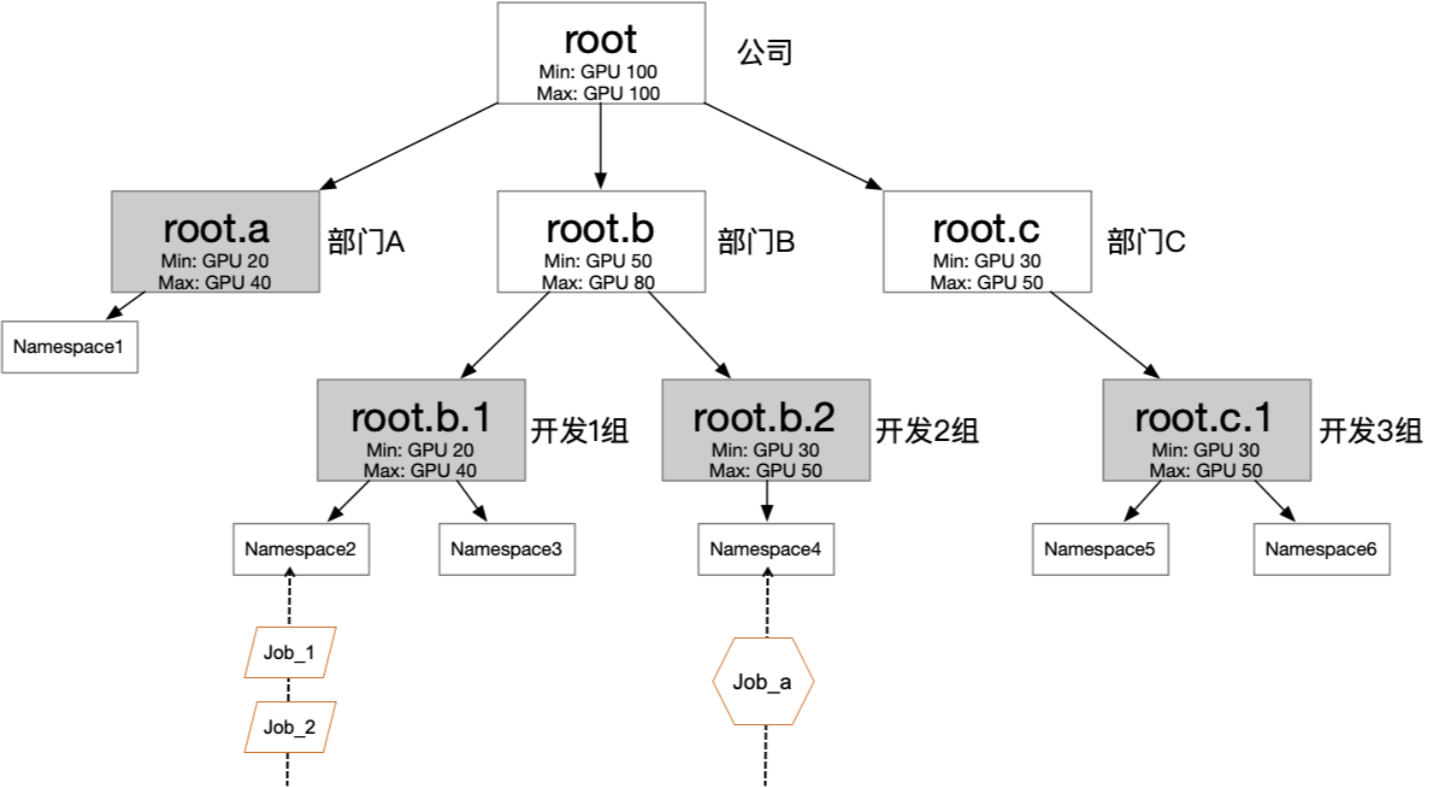
以下圖的公司組織結構為例,您可以根據具體情況,配置多個層級的彈性配額。圖中每個葉子結點,可對應一個用戶組,通過給用戶組中的用戶分配不同的namespace和role,可以將權限管理和配額管理分開。既可以在組間共享資源,又可以在組內實現隔離。
前提條件
已創建ACK Pro版集群,且在組件配置頁面,需要選中監控插件和日志服務。具體操作,請參見創建ACK Pro版集群。
ACK Pro版集群的Kubernetes版本不低于1.18。
目標任務
本指南將指導您完成以下目標任務:
安裝云原生AI套件。
查看資源大盤。
以組為單位分配集群配額。
管理用戶和用戶組。
利用集群空閑資源,提交超出至少可用資源的工作負載。
限制用戶使用的最大資源配額。
保證用戶隨時可用的資源配額。
步驟一:安裝云原生AI套件
云原生AI套件作為一款插件化的工具集,包括任務彈性、數據加速、AI任務調度、AI任務生命周期管理、集群運維控制臺、端到端研發控制臺等組件。您可以根據實際需要自由選擇安裝。
部署云原生AI套件
登錄容器服務管理控制臺。
在控制臺左側導航欄,單擊集群。
在集群列表頁面,單擊目標集群名稱或者目標集群右側操作列下的詳情。
在集群管理頁左側導航欄,選擇。
- 在云原生AI套件頁面,單擊一鍵部署。
- 在一鍵部署云原生AI套件頁面,根據需要選中相應的組件后,單擊頁面下方的部署云原生AI套件,開始檢查環境和依賴項,檢查通過后,自動部署選擇的組件。說明
- 交互方式下的Arena命名行(必選)為默認必選組件。
- 選中云原生AI運維控制臺時,會彈出提示話框。具體操作,請參見步驟1。
組件安裝成功后,在組件列表頁面:- 您能看到當前集群中已經安裝的組件名稱、版本等信息,并能對組件進行部署、卸載操作。
- 如果已安裝的組件有新版本的話,還可以對組件進行升級操作。
- 安裝了云原生AI運維控制臺組件(ack-ai-dashboard)后,您可在頁面左上方看到運維控制臺訪問地址,通過該地址可以訪問運維控制臺頁面。
安裝配置云原生AI運維控制臺
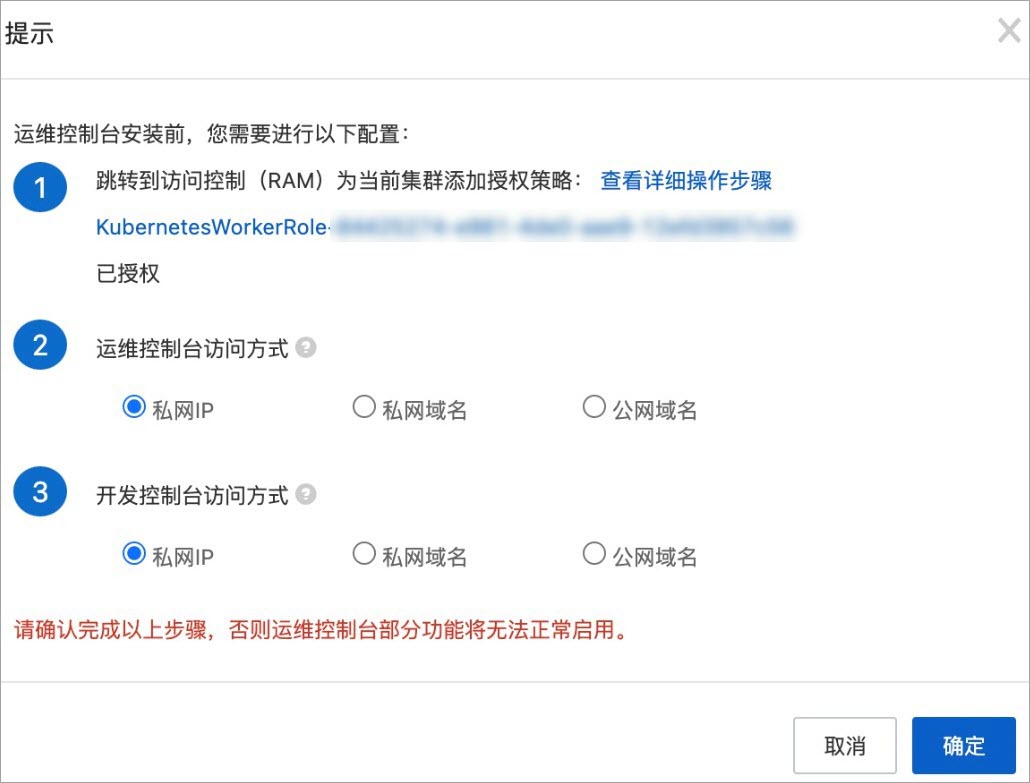
在云原生AI套件部署頁面的交互方式區域,選中控制臺,彈出提示對話框。
創建自定義權限策略并對RAM角色進行授權。
創建自定義權限策略。
登錄RAM控制臺,在左側導航欄選擇權限管理>權限策略。
單擊創建權限策略。
單擊腳本編輯頁簽。將以下策略添加至
Action字段中,然后單擊繼續編輯基本信息。"log:GetProject", "log:GetLogStore", "log:GetConfig", "log:GetMachineGroup", "log:GetAppliedMachineGroups", "log:GetAppliedConfigs", "log:GetIndex", "log:GetSavedSearch", "log:GetDashboard", "log:GetJob", "ecs:DescribeInstances", "ecs:DescribeSpotPriceHistory", "ecs:DescribePrice", "eci:DescribeContainerGroups", "eci:DescribeContainerGroupPrice", "log:GetLogStoreLogs", "ims:CreateApplication", "ims:UpdateApplication", "ims:GetApplication", "ims:ListApplications", "ims:DeleteApplication", "ims:CreateAppSecret", "ims:GetAppSecret", "ims:ListAppSecretIds", "ims:ListUsers"在頁面頂端的名稱文本框中輸入自定義權限策略的名稱,格式需設置為
k8sWorkerRolePolicy-{ClusterID},單擊確定。
對目標容器集群的RAM角色授權。
登錄RAM控制臺,在左側導航欄選擇身份管理>角色。
在文本框中輸入目標角色名稱,格式為
KubernetesWorkerRole-{ClusterID}。單擊目標角色名稱后操作列的新增授權。在選擇權限區域,單擊自定義策略。
在文本框中輸入之前創建的自定義權限策略名稱,格式為
k8sWorkerRolePolicy-{ClusterID}。單擊確定。
返回容器服務ACK控制臺的提示對話框,單擊授權檢測。如果授權成功,授權狀態顯示為已授權,且確定按鈕可用。請執行步驟3。
選擇控制臺數據存儲方式。
本文以選擇集群內置MySQL為例進行說明,實際使用時可替換為阿里云RDS。詳細說明,請參見安裝配置云原生AI運維控制臺。
單擊部署云原生AI套件。
待運維控制臺處于Ready狀態后,即可正常使用。
初始化數據集(可選)
管理員可按照算法開發人員的需求,創建和加速數據集。這里演示如何通過運維控制臺或命令行創建數據集。
fashion-mnist數據集
管理員通過kubectl命令行在可以訪問集群的機器上,新建OSS類型的PV和PVC。
根據以下YAML示例創建命名空間namespace: demo-ns。
kubectl create ns demo-ns根據YAML示例新建fashion-mnist.yaml。
apiVersion: v1
kind: PersistentVolume
metadata:
name: fashion-demo-pv
spec:
accessModes:
- ReadWriteMany
capacity:
storage: 10Gi
csi:
driver: ossplugin.csi.alibabacloud.com
volumeAttributes:
bucket: fashion-mnist
otherOpts: "-o max_stat_cache_size=0 -o allow_other"
url: oss-cn-beijing.aliyuncs.com
akId: "AKID"
akSecret: "AKSECRET"
volumeHandle: fashion-demo-pv
persistentVolumeReclaimPolicy: Retain
storageClassName: oss
volumeMode: Filesystem
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fashion-demo-pvc
namespace: demo-ns
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
selector:
matchLabels:
alicloud-pvname: fashion-demo-pv
storageClassName: oss
volumeMode: Filesystem
volumeName: fashion-demo-pv配置項 | 說明 |
name: fashion-demo-pv | 設定PV持久卷的名稱。與PVC持久卷聲明name: fashion-demo-pvc對應。 |
storage: 10Gi | 設定該PV的存儲容量為10GiB。 |
bucket: fashion-mnist | 設定OSS bucket的名稱。 |
url: oss-cn-beijing.aliyuncs.com | 設定您OSS服務的endpoint,示例中指的是阿里云北京區域的OSS服務地址。 |
akId: "AKID" akSecret: "AKSECRET" | 分別用來設定阿里云的AccessKey ID和Access Key Secret,用于認證和授權訪問OSS資源。 |
namespace: demo-ns | 設定命名空間的名稱。 |
執行YAML示例文件創建PV和PVC。
kubectl create -f fashion-mnist.yaml查看確認PV和PVC狀態。
執行以下命令,確認PV狀態。
kubectl get pv fashion-demo-pv -ndemo-ns預期輸出:
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE fashion-demo-pv 10Gi RWX Retain Bound demo-ns/fashion-demo-pvc oss 8h執行以下命令,確認PVC狀態。
kubectl get pvc fashion-demo-pvc -ndemo-ns預期輸出:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE fashion-demo-pvc Bound fashion-demo-pv 10Gi RWX oss 8h
創建加速數據集
管理員可通過AI運維控制臺加速目標數據集。本示例介紹如何對demo-ns命名空間下的fashion-demo-pvc數據集進行加速。
- 使用管理員賬號訪問AI運維控制臺。
- 在AI運維控制臺左側導航欄中,選擇。
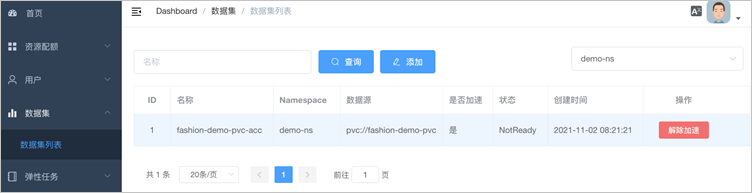
在數據集列表頁面,單擊目標數據集右側操作列的一鍵加速。
加速后的數據集如下圖所示:
步驟二:查看資源大盤
云原生AI套件中的運維控制臺,提供了集群資源大盤,可多維度查看集群實時使用情況,方便調優集群資源分配,優化集群資源使用率。
集群監控大盤
打開云原生AI運維控制臺后,默認進入的是集群監控大盤頁面。集群監控大盤可供您查看以下指標:
GPU Summary Of Cluster:展示集群中總的GPU節點數、已分配的GPU節點數、不健康的GPU節點數。
Total GPU Nodes:集群中總的GPU節點數。
Unhealthy GPU Nodes:不健康的GPU節點數。
GPU Memory(Used/Total):集群已使用GPU顯存與總的GPU顯存的百分比。
GPU Memory(Allocated/Total):集群已分配GPU顯存與總的GPU顯存百分比。
GPU Utilization:集群GPU的平均利用率。
GPUs(Allocated/Total):集群已分配GPU卡的個數與總的GPU卡數的百分比。
Training Job Summary Of Cluster:集群中各種狀態(Running、Pending、Succeeded、Failed)的訓練任務數。
節點監控大盤
在集群監控大盤頁面,單擊右上角的Nodes,進入節點監控大盤。節點監控大盤可供您查看以下指標:
GPU Node Details:以表格的形式展示集群節點的相關信息,包括:節點名稱(Name)、節點在集群中的IP(IP)、節點在集群中的角色(Role)、節點的狀態(Status)、GPU模式:獨占或共享(GPU Mode)、節點擁有GPU卡的個數(Total GPUs)、節點擁有的總GPU顯存(Total GPU Memory)、節點已分配GPU卡數(Allocated GPUs)、節點已分配GPU顯存(Allocated GPU Memory)、節點已使用GPU顯存(Used GPU Memory)、節點GPU平均使用率(GPU Utilization)。
GPU Duty Cycle:每個節點的每個GPU的使用率。
GPU Memory Usage:每個節點的每個GPU的顯存使用量。
GPU Memory Usage Percentage:每個節點的每個GPU的顯存使用百分比。
Allocated GPUs Per Node:每個節點已分配的GPU卡數。
GPU Number Per Node:每個節點的總GPU卡數。
Total GPU Memory Per Node:每個節點的總GPU顯存。
訓練任務監控大盤
在節點監控大盤頁面,單擊右上角TrainingJobs,進入訓練任務的監控大盤。訓練任務監控大盤可供您查看以下指標:
Training Jobs:通過表格的形式展示各個訓練任務的情況,包括:訓練任務所在命名空間(Namespace)、訓練任務名稱(Job Name)、訓練任務類型(Job Type)、訓練任務狀態(Job Status)、訓練任務持續時間(Duration)、訓練任務請求GPU卡數(Request GPUs)、訓練任務請求的GPU顯存(Allocated GPU Memory)、訓練任務當前使用的GPU顯存(Used GPU Memory)、訓練任務的GPU平均利用率(GPU Utilization)。
Job Instance Used GPU Memory:訓練任務中的各個實例的已使用GPU顯存。
Job Instance Used GPU Memory Percentage:訓練任務中各個實例使用GPU顯存的百分比。
Job Instance GPU Duty Cycle:訓練任務中各個實例的GPU利用率。
資源配額監控大盤
在訓練任務監控大盤頁面,單擊右上角的Quota,進入資源配額監控大盤。資源配額監控大盤可供您查看以下指標:Quota(cpu)、Quota(memory)、Quota(nvidia.com/gpu)、Quota(aliyun.com/gpu-mem)、Quota(aliyun.com/gpu)。每一個指標都以表格的形式展示以下資源配額的相關信息:
Elastic Quota Name:資源配額的名稱。
Namespace:資源所屬的Namespace。
Resource Name:資源類型的名稱。
Max Quota:您在某個Namespace下某種資源所使用的上限。
Min Quota:當整個集群資源緊張時,您在某個Namespace下可以使用的保障資源。
Used Quota: 您在某個Namespace下,某種資源的已使用值。
步驟三:管理用戶和配額
云原生AI套件通過用戶(User)、用戶組(UserGroup)、配額樹(QuotaTree)/配額節點(QuotaNode)、K8s Namespace等實體來管理用戶和配額。這些概念的關聯關系,如下圖所示。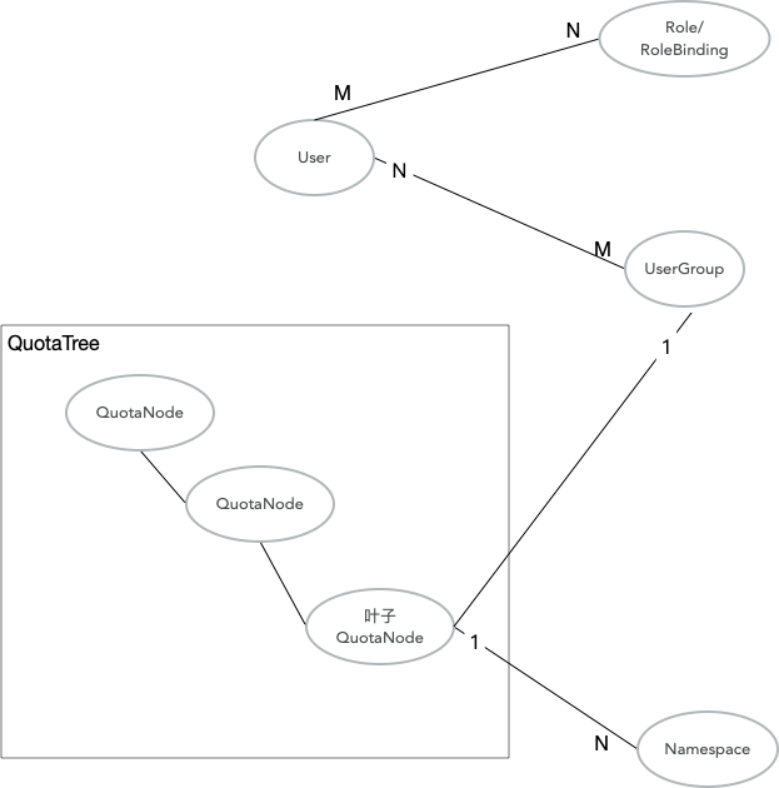
配額樹是配置多層級約束的資源,供Capacity Scheduling Plugin使用。可以確保用戶資源分配的基礎上通過資源共享的方式來提升集群的整體資源利用率。
云原生AI套件的用戶一一對應一個K8s ServiceAccount,是提交任務和登錄控制臺的憑證。用戶根據用戶類型確定權限,其中admin負責運維集群,可登錄運維控制臺;researcher負責提交任務,使用集群資源,可登錄開發控制臺;admin包含researcher的所有權限。
用戶組是資源分配的最小單位,并與QuotaTree的葉子節點一一對應。用戶必須關聯用戶組,才能使用與之關聯的配額資源。
本步驟將介紹如何通過配額樹來配置多層級的配額約束、通過用戶組來分配配額給組用戶以及通過提交簡單的任務,演示CPU資源的彈性借還。
添加配額節點,并限定資源使用額度
配額是通過設置各資源的Min/Max來配置額度,其中Min表示有保障的資源數量(Guaranteed Resource),Max表示最大可用的資源數。把namespace掛載在配額樹的葉子節點,就意味著namespace受根節點到當前葉子結點路徑上的所有約束。
如果namespace不存在,需要提前手動創建namespace。如果namespace已存在,需要保證namespace下沒有Running的Pod。
kubectl create ns namespace1 kubectl create ns namespace2 kubectl create ns namespace3 kubectl create ns namespace4創建配額節點,并關聯namespace。
創建用戶和用戶組
用戶和用戶組是多對多的關系,一個用戶可以屬于多個用戶組,一個用戶組也以可有多個用戶。您可以通過用戶關聯用戶組,也可以通過用戶組關聯用戶。通過配額樹和用戶組,可以方便的根據實際項目組劃分資源,分配權限。
創建用戶。具體操作請參見為新增用戶生成KubeConfig和登錄Token。
創建用戶組。具體操作請參見新增用戶組。
Capacity調度功能演示
本演示將通過創建CPU Pod,演示Capacity調度功能如何借用和搶占資源,從而保證每個配額節點的Min和Max約束。演示的設計流程如下所示:
通過配置root節點的Min和Max均為40,使得配額樹整體擁有資源40核CPU。
使root.a和root.b均分CPU資源,各保障有20核,最大可利用40核。
root.a.1、root.a.2及root.b.1、root.b.2,各保障10核,最大可利用20核。
通過提交一個5副本的任務(5副本 x 5核/副本=25核)到namespace1,預期可成功運行4個副本(4副本 x 5核/副本=20核),即root.a.1的Max(最大可用配額)。
通過提交一個5副本的任務(5副本 x 5核/副本=25核)到namespace2,預期可成功運行4個副本(4副本 x 5核/副本=20核),即root.a.2的Max(最大可用配額)。
通過提交一個5副本的任務(5副本 x 5核/副本=25核)到namespace3,預期可成功運行2個副本(2副本 x 5核/副本=10核),即root.b.1的Min(最少可用配額)。這時調度器會綜合優先級、可用性以及創建時間等因素,選擇root.a下相應的Pod搶占,歸還之前搶占的資源。考慮到公平性,root.a.1和root.a.2的pod會分別被搶占一個。這時namespace1和namespace2下分別有3個副本(皆為:3副本 x 5核/副本=15核)
通過提交一個5副本的任務(5副本 x 5核/副本=25核)到namespace4,預期可成功運行2個副本(2副本 x 5核/副本=10核),即root.b.2的Min(最少可用配額)。
具體操作步驟如下所示。
新建namespace及配額樹。
執行以下命令,分別創建四個對應的Namespace。
已創建namespace1為例:
kubectl create ns namespace1 kubectl create ns namespace2 kubectl create ns namespace3 kubectl create ns namespace4根據下圖,建立配額樹。
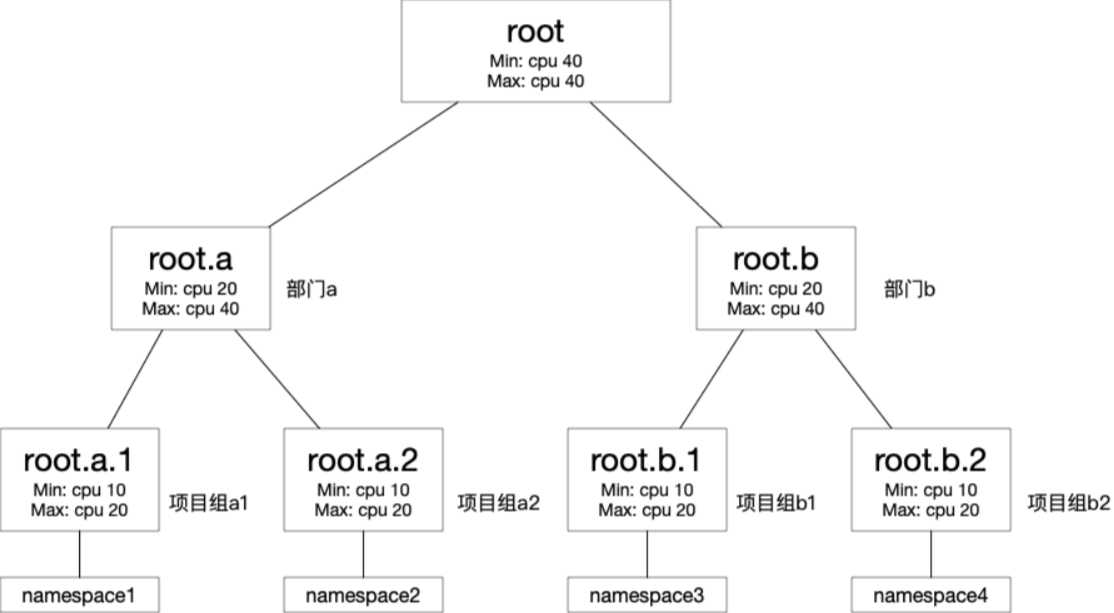
使用以下YAML文件樣例,在namespace1中部署服務,Pod的副本數為5個,每個Pod請求CPU資源量為5核。
如果沒有彈性配額,用戶最多只能使用10核(cpu.min=10),也就是建立2個副本。但在彈性配額Capacity調度下:
當集群有空閑的40核CPU時,可以創建4個副本(4副本 x 5核/副本=20核)。
最后一個副本因為超出最大資源限制(cpu.max=20),處于Pending狀態。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx1 namespace: namespace1 labels: app: nginx1 spec: replicas: 5 selector: matchLabels: app: nginx1 template: metadata: name: nginx1 labels: app: nginx1 spec: containers: - name: nginx1 image: nginx resources: limits: cpu: 5 requests: cpu: 5使用以下YAML文件樣例,在namespace2中部署服務,Pod的副本數為5個,每個Pod請求CPU資源量為5核。
如果沒有彈性配額,用戶最多只能使用10個cpu(cpu.min=10),只能建立2個副本。但在彈性配額Capacity調度下:
在集群資源有20核(40核-namespace1中的20核)空閑,可以創建4個副本(4副本 x 5核/副本=20核)。
最后一個副本因為超出最大資源限制(cpu.max=20),處于Pending狀態。
此時集群中namespace1和namespace2中的Pod所占用的資源已經達到了root設置的root.max.cpu=40。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx2 namespace: namespace2 labels: app: nginx2 spec: replicas: 5 selector: matchLabels: app: nginx2 template: metadata: name: nginx2 labels: app: nginx2 spec: containers: - name: nginx2 image: nginx resources: limits: cpu: 5 requests: cpu: 5使用以下YAML文件樣例,在namespace3中部署服務,其中Pod的副本數為5,每個Pod請求CPU資源量為5核。
集群無資源空閑,但是為了保障root.b.1的Min(最少可用配額),需要搶占root.a中的pod歸還10核。
調度器會綜合考慮root.a下作業的優先級、可用性以及創建時間等因素,選擇相應的Pod歸還之前搶占的資源(10核)。因此,nginx3得到配額min.cpu=10的資源量后,有2個Pod處于Running狀態,其他3個仍處于Pending狀態。
root.a被搶占后,namespace1下有2個pod處于Running,3個處于Pending;namespace2下也有2個pod處于Running,3個處于Pending。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx3 namespace: namespace3 labels: app: nginx3 spec: replicas: 5 selector: matchLabels: app: nginx3 template: metadata: name: nginx3 labels: app: nginx3 spec: containers: - name: nginx3 image: nginx resources: limits: cpu: 5 requests: cpu: 5使用以下YAML文件樣例,在namespace4中部署服務,其中Pod的副本數為5個,每個Pod請求CPU資源量為5核
這時調度器會綜合優先級、可用性以及創建時間等因素,選擇root.a下相應的Pod搶占,歸還之前搶占的資源。
考慮到公平性,root.a.1和root.a.2的pod會分別被搶占一個。這時,在namespace1下有2個pod*5核/副本=10核。在namespace2下,也有2個pod*5核/副本=10核。這時namespace1和namespace2下分別有2個副本(皆為:2副本 x 5核/副本=10核)。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx4 namespace: namespace4 labels: app: nginx4 spec: replicas: 5 selector: matchLabels: app: nginx4 template: metadata: name: nginx4 labels: app: nginx4 spec: containers: - name: nginx4 image: nginx resources: limits: cpu: 5 requests: cpu: 5
通過以上演示,有效驗證了Capacity調度在彈性分配資源中的優勢。