基于GPU指標實現(xiàn)彈性伸縮
Kubernetes提供了Custom Metrics機制,該機制可以對接阿里云Prometheus監(jiān)控來采集GPU指標。本文介紹如何部署阿里云Prometheus監(jiān)控,并結(jié)合示例說明如何通過阿里云Prometheus監(jiān)控觀測GPU指標,實現(xiàn)容器的彈性伸縮。
前提條件
功能介紹
在高性能計算領(lǐng)域,例如深度學習模型訓練、推理等場景,通常需要使用GPU來做計算加速。為了節(jié)省成本,您可以根據(jù)GPU指標(利用率、顯存)來進行彈性伸縮。
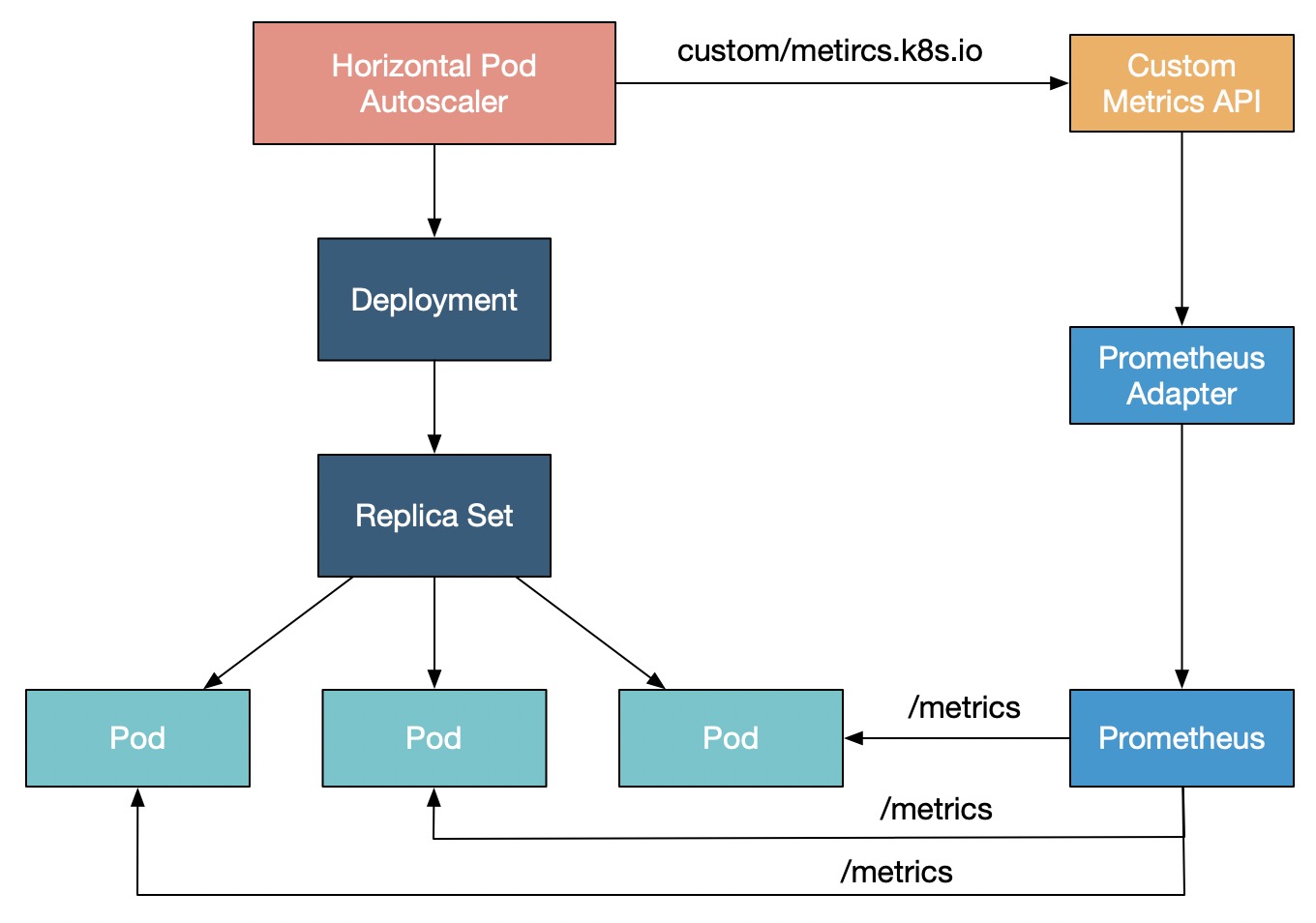
Kubernetes默認提供CPU和內(nèi)存作為HPA彈性伸縮的指標。如果有更復雜的場景需求,例如基于GPU指標進行自動擴縮容,您可以通過Prometheus Adapter適配Prometheus采集到的GPU指標,再利用Custom Metrics API來對HPA的指標進行擴展,從而根據(jù)GPU利用率、顯存等指標進行彈性伸縮。GPU彈性伸縮原理如下圖所示:
步驟一:部署阿里云Prometheus和Metrics Adapter
- 說明
如果您在創(chuàng)建集群時,已選中安裝Prometheus,則不需要重復安裝。
安裝并配置ack-alibaba-cloud-metrics-adapter。
一、獲取HTTP API地址
登錄ARMS控制臺。
在左側(cè)導航欄選擇,進入可觀測監(jiān)控 Prometheus 版的實例列表頁面。
在頁面頂部選擇容器服務K8s集群所在的地域,然后單擊目標實例名稱,進入對應實例頁面。
在當前設置頁面的設置頁簽下的HTTP API地址區(qū)域,復制HTTP API地址下的內(nèi)網(wǎng)地址。
二、配置Prometheus Url
登錄容器服務管理控制臺,在左側(cè)導航欄選擇。
在應用市場頁面單擊應用目錄頁簽,搜索并單擊ack-alibaba-cloud-metrics-adapter。
在ack-alibaba-cloud-metrics-adapter頁面,單擊一鍵部署。
在基本信息配置向?qū)е校x擇集群和命名空間,然后單擊下一步。
在參數(shù)配置配置向?qū)е校x擇Chart版本,在參數(shù)配置中將上述獲取的HTTP API地址設置為Prometheus的
url值,然后單擊確定。
步驟二:配置GPU指標Adapter Rules
一、查詢GPU指標
查詢GPU相關(guān)指標。詳細信息,請參見監(jiān)控指標說明。
二、配置Adapter Rules
登錄容器服務管理控制臺,在左側(cè)導航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側(cè)導航欄,選擇。
在Helm列表的操作列,單擊ack-alibaba-cloud-metrics-adapter對應的更新。在
custom字段下添加如下rules。- metricsQuery: avg(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>) resources: overrides: NodeName: resource: node seriesQuery: DCGM_FI_DEV_GPU_UTIL{} # GPU使用率 - metricsQuery: avg(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>) resources: overrides: NamespaceName: resource: namespace NodeName: resource: node PodName: resource: pod seriesQuery: DCGM_CUSTOM_PROCESS_SM_UTIL{} # 容器GPU使用率。 - metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>) resources: overrides: NodeName: resource: node seriesQuery: DCGM_FI_DEV_FB_USED{} # 顯存使用量。 - metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>) resources: overrides: NamespaceName: resource: namespace NodeName: resource: node PodName: resource: pod seriesQuery: DCGM_CUSTOM_PROCESS_MEM_USED{} # 容器顯存使用量。 - metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>) / sum(DCGM_CUSTOM_CONTAINER_MEM_ALLOCATED{}) by (<<.GroupBy>>) name: as: ${1}_GPU_MEM_USED_RATIO matches: ^(.*)_MEM_USED resources: overrides: NamespaceName: resource: namespace PodName: resource: pod seriesQuery: DCGM_CUSTOM_PROCESS_MEM_USED{NamespaceName!="",PodName!=""} # 容器GPU顯存使用率。添加后效果如下。

執(zhí)行以下命令時,存在HPA可以識別的輸出條目
DCGM_FI_DEV_GPU_UTIL、DCGM_CUSTOM_PROCESS_SM_UTIL、DCGM_FI_DEV_FB_USED、DCGM_CUSTOM_PROCESS_MEM_USED指標,則說明配置成功生效。下面以DCGM_CUSTOM_PROCESS_SM_UTIL為例進行說明,實際以輸出為準。kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" { [ ... { "name": "nodes/DCGM_CUSTOM_PROCESS_SM_UTIL", "singularName": "", "namespaced": false, "kind": "MetricValueList", "verbs": [ "get" ] }, ... { "name": "pods/DCGM_CUSTOM_PROCESS_SM_UTIL", "singularName": "", "namespaced": true, "kind": "MetricValueList", "verbs": [ "get" ] }, ... { "name": "namespaces/DCGM_CUSTOM_PROCESS_SM_UTIL", "singularName": "", "namespaced": false, "kind": "MetricValueList", "verbs": [ "get" ] } ... { "name": "DCGM_CUSTOM_PROCESS_GPU_MEM_USED_RATIO", "singularName": "", "namespaced": false, "kind": "MetricValueList", "verbs": [ "get" ] } ... ] }
步驟三:基于GPU指標實現(xiàn)彈性伸縮
本示例通過在GPU上部署一個模型推理服務,然后對其進行壓測,根據(jù)GPU利用率測試彈性伸縮。
一、部署推理服務
執(zhí)行以下命令部署推理服務。
cat <<EOF | kubectl create -f - apiVersion: apps/v1 kind: Deployment metadata: name: bert-intent-detection spec: replicas: 1 selector: matchLabels: app: bert-intent-detection template: metadata: labels: app: bert-intent-detection spec: containers: - name: bert-container image: registry.cn-hangzhou.aliyuncs.com/ai-samples/bert-intent-detection:1.0.1 ports: - containerPort: 80 resources: limits: nvidia.com/gpu: 1 --- apiVersion: v1 kind: Service metadata: name: bert-intent-detection-svc labels: app: bert-intent-detection spec: selector: app: bert-intent-detection ports: - protocol: TCP name: http port: 80 targetPort: 80 type: LoadBalancer EOF查看Pod和Service狀態(tài)。
執(zhí)行以下命令查看Pod狀態(tài)。
kubectl get pods -o wide預期輸出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES bert-intent-detection-7b486f6bf-f**** 1/1 Running 0 3m24s 10.15.1.17 cn-beijing.192.168.94.107 <none> <none>預期輸出表明,當前只有一個Pod部署在192.168.94.107這個GPU節(jié)點上。
執(zhí)行以下命令查看Service狀態(tài)。
kubectl get svc bert-intent-detection-svc預期輸出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE bert-intent-detection-svc LoadBalancer 172.16.186.159 47.95.XX.XX 80:30118/TCP 5m1s預期輸出中顯示服務名稱,表示服務部署成功。
通過SSH登錄GPU節(jié)點192.168.94.107后,執(zhí)行以下命令查看GPU使用情況。
nvidia-smi預期輸出:
Wed Feb 16 11:48:07 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 32C P0 55W / 300W | 15345MiB / 16160MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 2305118 C python 15343MiB | +-----------------------------------------------------------------------------+預期輸出表明,推理服務進程已運行在GPU上。由于尚未發(fā)起請求,當前GPU利用率為0。
執(zhí)行以下命令調(diào)用推理服務,驗證部署是否成功。
curl -v "http://47.95.XX.XX/predict?query=Music"預期輸出:
* Trying 47.95.XX.XX... * TCP_NODELAY set * Connected to 47.95.XX.XX (47.95.XX.XX) port 80 (#0) > GET /predict?query=Music HTTP/1.1 > Host: 47.95.XX.XX > User-Agent: curl/7.64.1 > Accept: */* > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < Content-Type: text/html; charset=utf-8 < Content-Length: 9 < Server: Werkzeug/1.0.1 Python/3.6.9 < Date: Wed, 16 Feb 2022 03:52:11 GMT < * Closing connection 0 PlayMusic # 意圖識別結(jié)果。預期輸出中,HTTP請求返回狀態(tài)碼200并返回意圖識別結(jié)果,表明推理服務部署成功。
二、配置HPA
本文以GPU利用率為例進行說明,當Pod的GPU利用率大于20%時,觸發(fā)擴容。HPA目前支持的指標如下。
指標名稱 | 說明 | 單位 |
DCGM_FI_DEV_GPU_UTIL |
| % |
DCGM_FI_DEV_FB_USED |
| MiB |
DCGM_CUSTOM_PROCESS_SM_UTIL | 容器的GPU利用率。 | % |
DCGM_CUSTOM_PROCESS_MEM_USED | 容器的GPU顯存使用量。 | MiB |
DCGM_CUSTOM_PROCESS_GPU_MEM_USED_RATIO | 容器的GPU顯存利用率。
| % |
執(zhí)行以下命令部署HPA。
集群版本≥1.23
cat <<EOF | kubectl create -f - apiVersion: autoscaling/v2 # 使用autoscaling/v2版本的HPA配置。 kind: HorizontalPodAutoscaler metadata: name: gpu-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: bert-intent-detection minReplicas: 1 maxReplicas: 10 metrics: - type: Pods pods: metric: name: DCGM_CUSTOM_PROCESS_SM_UTIL target: type: Utilization averageValue: 20 # 當容器的GPU利用率超過20%,觸發(fā)擴容。 EOF集群版本<1.23
cat <<EOF | kubectl create -f - apiVersion: autoscaling/v2beta1 # 使用autoscaling/v2beta1版本的HPA配置。 kind: HorizontalPodAutoscaler metadata: name: gpu-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: bert-intent-detection minReplicas: 1 maxReplicas: 10 metrics: - type: Pods pods: metricName: DCGM_CUSTOM_PROCESS_SM_UTIL # Pod的GPU利用率。 targetAverageValue: 20 # 當容器的GPU利用率超過20%,觸發(fā)擴容。 EOF執(zhí)行以下命令查看HPA狀態(tài)。
kubectl get hpa預期輸出:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-intent-detection 0/20 1 10 1 74s預期輸出表明,
TARGETS為0/20,即當前GPU利用率為0,當GPU利用率超過20%時觸發(fā)彈性擴容。
三、測試推理服務彈性伸縮
測試擴容效果
執(zhí)行以下命令進行壓測。
hey -n 10000 -c 200 "http://47.95.XX.XX/predict?query=music"說明HPA彈性擴容的期望副本數(shù)的計算公式:
期望副本數(shù) = ceil[當前副本數(shù) * (當前指標 / 期望指標)]。例如,當前副本數(shù)為1,當前指標為23,期望指標為20,由計算公式得到期望副本數(shù)為2。壓測過程中,觀察HPA和Pod的狀態(tài)。
執(zhí)行以下命令查看HPA的狀態(tài)。
kubectl get hpa預期輸出:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-intent-detection 23/20 1 10 2 7m56s預期輸出表明,
TARGETS值為23/20,當前GPU利用率超過20%時,觸發(fā)彈性伸縮,此時集群開始擴容。執(zhí)行以下命令查看Pod的狀態(tài)。
kubectl get pods預期輸出:
NAME READY STATUS RESTARTS AGE bert-intent-detection-7b486f6bf-f**** 1/1 Running 0 44m bert-intent-detection-7b486f6bf-m**** 1/1 Running 0 14s預期輸出表明,當前有2個Pod。由上述計算公式得到Pod總數(shù)應為2,公式計算值與實際輸出一致。
HPA和Pod的預期輸出,Pod擴容成功。
測試縮容效果
當壓測停止,GPU利用率降低且低于20%后,系統(tǒng)開始進行彈性縮容。
執(zhí)行以下命令查看HPA的狀態(tài)。
kubectl get hpa預期輸出:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-intent-detection 0/20 1 10 1 15m預期輸出表明,
TARGETS為0/20,即當前GPU利用率為0,大約5分鐘后,系統(tǒng)開始進行彈性縮容。執(zhí)行以下命令查看Pod的狀態(tài)。
kubectl get pods預期輸出:
NAME READY STATUS RESTARTS AGE bert-intent-detection-7b486f6bf-f**** 1/1 Running 0 52m預期輸出表明,當前Pod個數(shù)為1,即縮容成功。
常見問題
如何判斷是否使用了GPU卡?
您可以通過GPU監(jiān)控頁簽,觀察GPU卡的使用率波動狀況,以此判斷GPU卡是否被使用。如果使用率上升,表明使用了GPU卡。如果使用率不變,表明未使用GPU卡。詳細方法為:
登錄容器服務管理控制臺,在左側(cè)導航欄中單擊集群。
在集群列表頁面中,單擊目標集群名稱,然后在左側(cè)導航欄中,選擇。
在Prometheus監(jiān)控頁面,單擊GPU監(jiān)控頁簽,然后觀察GPU卡的使用率波動狀況。