云原生多模數據庫 Lindorm支持Bulkload(批量快速導入數據)功能,可以更快更穩定的導入數據。本文介紹批量快速導入數據操作。
功能特性
批量快速導入數據功能支持數據文件旁路加載,不需要經過數據API寫入鏈路并且不需要占用實例計算資源,,批量快速導入數據與通過API導入數據相比有以下優勢:
導入數據更快,速度可以提升10倍以上。
在線服務更穩定,不占用在線服務資源。
資源使用更靈活,在離線資源中分開使用更加靈活。
支持多種數據源導入,包括CSV、ORC、Parquet、MaxCompute等。
使用簡單。您無需開發任何代碼就可以實現數據的批量快速旁路加載。
成本低。LTS Bulkload基于Serverless Spark提供的云原生彈性能力,根據您的需求提供彈性計算資源按量收費,您無需經常配置計算資源,可以降低使用成本。
前提條件
已開通并登錄LTS數據同步服務,具體操作請參見開通并登錄LTS。
已開通Lindorm計算引擎,具體操作請參見開通與變配。
已添加Spark數據源,具體操作請參見添加Spark數據源。
支持的數據源
源數據源 | 目標數據源 |
MaxCompute Table | Lindorm寬表引擎 |
HDFS CSV或者OSS CSV | |
HDFS Parquet或者OSS Parquet | |
HDFS ORC或者OSS ORC |
提交方式
快速導入數據任務支持以下方式提交。
通過LTS操作頁面提交
登錄LTS操作頁面,具體操作參見開通并登錄LTS。
在左側導航欄,選擇數據源管理 > 添加數據源,添加以下數據源。
添加ODPS數據源,具體操作請參見ODPS數據源。
添加Lindorm寬表數據源,具體操作請參見Lindorm寬表數據源。
添加HDFS數據源,具體操作請參見添加HDFS數據源。
在左側導航欄中,選擇。
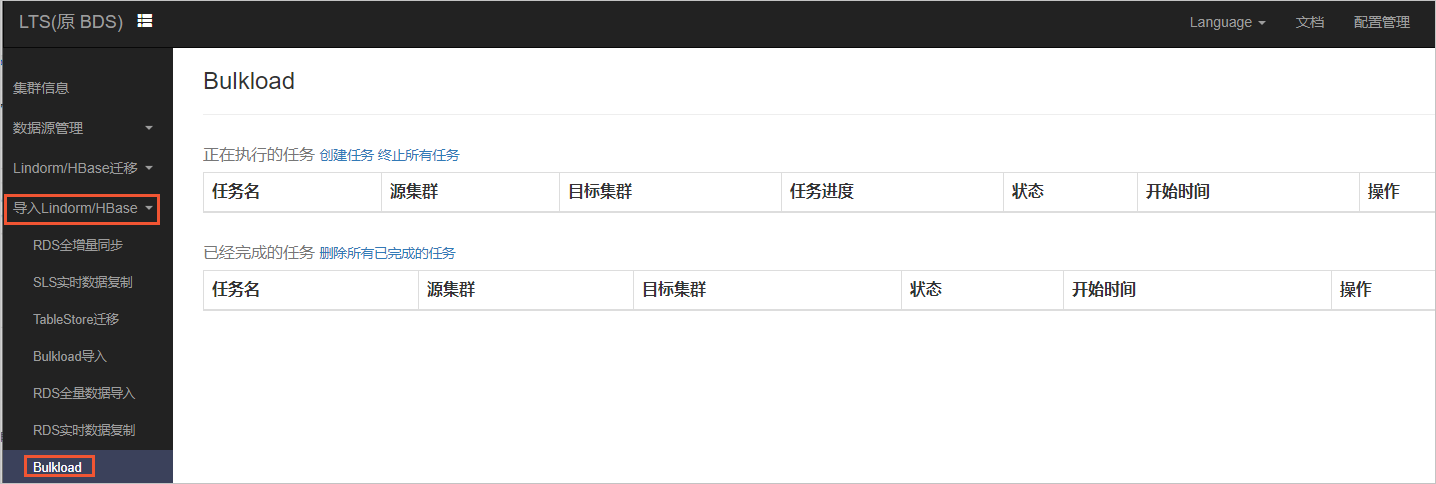
單擊創建任務,配置以下參數。
配置項
參數
描述
選擇數據源
源數據源
選擇添加的ODPS數據源或者HDFS數據源。
目標數據源
選擇添加的Lindorm寬表數據源。
插件配置
Reader配置
如果源數據源為ODPS數據源,讀插件配置說明如下:
table:ODPS的表名。
column:需要導入的ODPS列名。
partition:非分區表為空,分區表配置分區信息。
numPartitions:讀取時的并發度。
如果源數據源為HDFS數據源,CSV文件的讀插件配置說明如下:
filePath:CSV文件的所在目錄。
header:CSV文件是否包含header行。
delimite:CSV文件分隔符。
column:CSV文件中列名以及對應類型。
如果源數據源為HDFS數據源,Parquet文件的讀插件配置說明如下:
filePath:Parquet文件的所在目錄。
column:Parquet文件中的列名。
說明讀插件配置示例請參見配置示例。
Writer配置
namespace:Lindorm寬表的namespace。
lindormTable:Lindorm寬表名稱。
compression:壓縮算法,目前僅支持zstd,不使用壓縮算法配置為none。
columns:根據導入至目標表類型填寫。
如果導入至Lindorm寬表,columns需要配置Lindorm SQL寬表的列名,和讀配置中的column對應。
如果導入至Lindorm兼容HBase表,columns需要配置HBase表標準的列名,和讀配置中的column對應。
timestamp:數據在Lindorm寬表中的時間戳,支持以下類型:
時間戳列為Long類型,值為13位。
時間戳列為String類型,格式為yyyy-MM-dd HH:mm:ss或者yyyy-MM-dd HH:mm:ss SSS。
說明寫插件配置示例請參見配置示例。
作業運行參數配置
Spark Driver規格
選擇Spark Driver規格。
Spark Executor規格
選擇Spark Executor規格。
Executor數量
輸入Executor的數量。
spark配置
輸入Spark配置,可不填寫。
單擊創建。
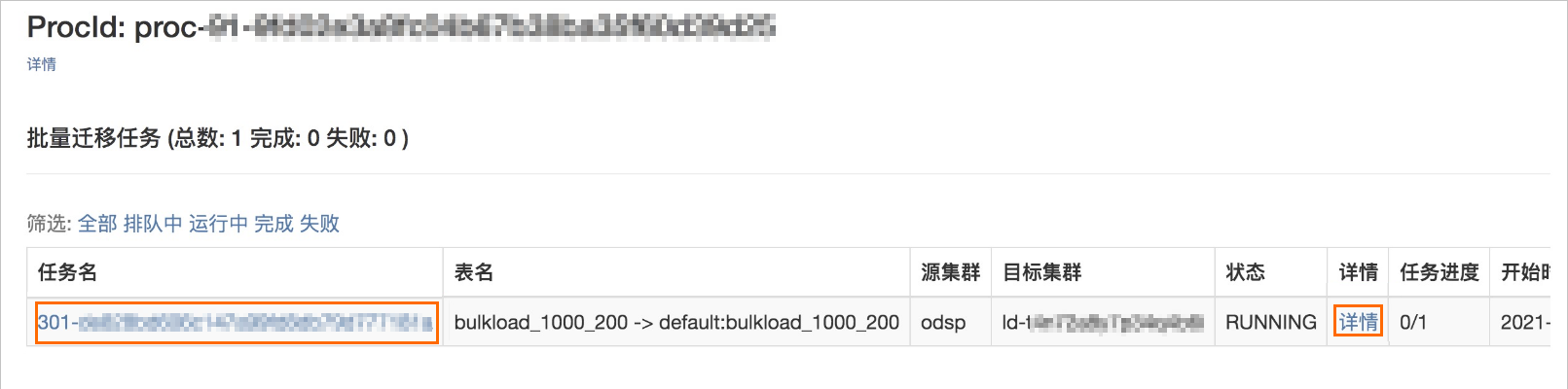
在Bulkload頁面單擊任務名查看快速導入數據任務。
單擊任務名,可以查看Spark任務的UI界面。
單擊詳情,可以查看Spark任務的執行日志。
 說明
說明源數據源遷移到Lindorm寬表,在Lindorm寬表不同分區的數據均勻情況下 , 數據容量為100 GB(壓縮比為1:4)壓縮后導入大概需要1個小時,根據具體情況不同可能會有區別。
通過API接口提交
提交任務接口
接口(POST):
http://{BDSMaster}:12311/pro/proc/bulkload/create,BDSMaster需要修改為Lindorm實例的Master hostname,可以登錄Lindorm實例的LTS,在集群信息頁面的基本信息區域獲取。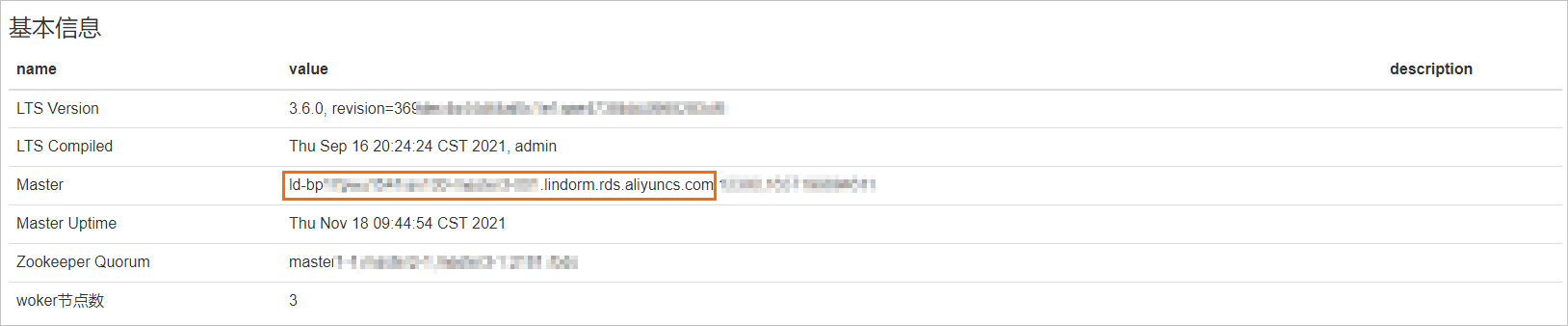
參數說明:
參數
說明
src
源數據源名稱。
dst
目標數據源名稱。
readerConfig
讀插件配置信息,文件類型為JSON,讀插件配置示例請參見配置示例。
writerConfig
寫插件配置信息,文件類型為JSON,寫插件配置示例請參見配置示例。
driverSpec
Driver的規格,包括small、medium、large和xlarge四種規格,推薦配置為large。
instances
Executor的數量。
fileType
如果源數據源為HDFS,需要填寫文件類型為CSV或者Parquet。
sparkAdditionalParams
擴展參數可以不填。
示例:
curl -d "src=hdfs&dst=ld&readerConfig={\"filePath\":\"parquet/\",\"column\":[\"id\",\"intcol\",\"doublecol\",\"stringcol\",\"string1col\",\"decimalcol\"]}&writerConfig={\"columns\":[\"ROW||String\",\"f:intcol||Int\",\"f:doublecol||Double\",\"f:stringcol||String\",\"f:string1col||String\",\"f:decimalcol||Decimal\"],\"namespace\":\"default\",\"lindormTable\":\"bulkload_test\",\"compression\":\"zstd\"}&driverSpec=large&instances=5&fileType=Parquet" -H "Content-Type: application/x-www-form-urlencoded" -X POST http://{LTSMaster}:12311/pro/proc/bulkload/create返回內容如下,message為任務ID。
{"success":"true","message":"proc-91-ff383c616e5242888b398e51359c****"}
獲取任務信息
接口(GET):
http://{LTSMaster}:12311/pro/proc/{procId}/info,LTSMaster需要修改為Lindorm實例的Master hostname,可以登錄Lindorm實例的LTS,在集群信息頁面的基本信息區域獲取。參數說明:procId表示任務ID。
示例:
curl http://{LTSMaster}:12311/pro/proc/proc-91-ff383c616e5242888b398e51359c****/info返回內容如下:
{ "data":{ "checkJobs":Array, "procId":"proc-91-ff383c616e5242888b398e51359c****", //任務ID "incrJobs":Array, "procConfig":Object, "stage":"WAIT_FOR_SUCCESS", "fullJobs":Array, "mergeJobs":Array, "srcDS":"hdfs", //源數據源 "sinkDS":"ld-uf6el41jkba96****", //目標數據源 "state":"RUNNING", //任務狀態 "schemaJob":Object, "procType":"SPARK_BULKLOAD" //任務類型 }, "success":"true" }
終止任務
接口(GET):
http://{LTSMaster}:12311/pro/proc/{procId}/abort,LTSMaster需要修改為Lindorm實例的Master hostname,可以登錄Lindorm實例的LTS,在集群信息頁面的基本信息區域獲取。參數說明:procId表示任務ID。
示例:
curl http://{LTSMaster}:12311/pro/proc/proc-91-ff383c616e5242888b398e51359c****/abort返回內容如下:
{"success":"true","message":"ok"}
重試任務
接口(GET):
http://{LTSMaster}:12311/pro/proc/{procId}/retry,LTSMaster需要修改為Lindorm實例的Master hostname,可以登錄Lindorm實例的LTS,在集群信息頁面的基本信息區域獲取。參數說明:procId表示任務ID。
示例:
curl http://{LTSMaster}:12311/pro/proc/proc-91-ff383c616e5242888b398e51359c****/retry返回結果如下:
{"success":"true","message":"ok"}
刪除任務
接口(GET):
http://{LTSMaster}:12311/pro/proc/{procId}/delete,LTSMaster需要修改為Lindorm實例的Master hostname,可以登錄Lindorm實例的LTS,在集群信息頁面的基本信息區域獲取。參數說明:procId表示任務ID。
示例:
curl http://{LTSMaster}:12311/pro/proc/proc-91-ff383c616e5242888b398e51359c****/delete返回結果如下:
{"success":"true","message":"ok"}
配置示例
讀插件配置示例。
源數據源為ODPS的讀插件配置示例。
{ "table": "test", "column": [ "id", "intcol", "doublecol", "stringcol", "string1col", "decimalcol" ], "partition": [ "pt=1" ], "numPartitions":10 }源數據源為HDFS,CSV文件的讀插件配置示例。
{ "filePath":"csv/", "header": false, "delimiter": ",", "column": [ "id|string", "intcol|int", "doublecol|double", "stringcol|string", "string1col|string", "decimalcol|decimal" ] }源數據源為HDFS,Parquet文件的讀插件配置示例。
{ "filePath":"parquet/", "column": [ //parquet文件中的列名 "id", "intcol", "doublecol", "stringcol", "string1col", "decimalcol" ] }
寫插件配置示例。
導入到Lindorm SQL表格的寫插件配置示例。
{ "namespace": "default", "lindormTable": "xxx", "compression":"zstd", "timestamp":"2022-07-01 10:00:00", "columns": [ "id", "intcol", "doublecol", "stringcol", "string1col", "decimalcol" ] }導入到Lindorm兼容HBase表格的寫插件配置示例。
{ "namespace": "default", "lindormTable": "xxx", "compression":"zstd", "timestamp":"2022-07-01 10:00:00", "columns": [ "ROW||String", //ROW代表rowkey,String表示類型 "f:intcol||Int", //列簇:列名||列類型 "f:doublecol||Double", "f:stringcol||String", "f:string1col||String", "f:decimalcol||Decimal" ] }