本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
本文介紹如何安裝X2Doris以及如何使用其導入數據至云數據庫 SelectDB 版。
工具介紹
X2Doris是將各種離線數據導入至云數據庫 SelectDB 版的重要工具。
工具優勢:
自動建表和數據導入為一體。
可視化平臺進行操作,簡單易用。
支持導入的數據源:Doris、Hive、Kudu、StarRocks和ClickHouse。
導入Hive源數據
安裝X2Doris
注意事項
安裝X2Doris的服務器必須是Hadoop集群的一個節點,或者是有Hadoop gateway環境(即該服務器上可以執行Hadoop和Hive的命令,能正常訪問Hadoop、Hive集群)。
部署X2Doris的機器必須配置了Hadoop環境變量,必須配置
HADOOP_HOME,HADOOP_CONF_DIR和HIVE_CONF_DIR,示例如下:重要在
HADOOP_CONF_DIR或HIVE_CONF_DIR下必須要有hive-site.xml。export HADOOP_HOME=/opt/hadoop #hadoop安裝目錄 export HADOOP_CONF_DIR=/etc/hadoop/conf #hadoop配置文件目錄 export HIVE_HOME=$HADOOP_HOME/../hive export HIVE_CONF_DIR=$HADOOP_HOME/conf export HBASE_HOME=$HADOOP_HOME/../hbase export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn
安裝環境
本文以Linux系統為例,安裝X2Doris工具。您在實際使用中,請根據您的系統和使用環境選擇合適的命令。
操作步驟
選擇X2Doris工具版本。
有Spark環境
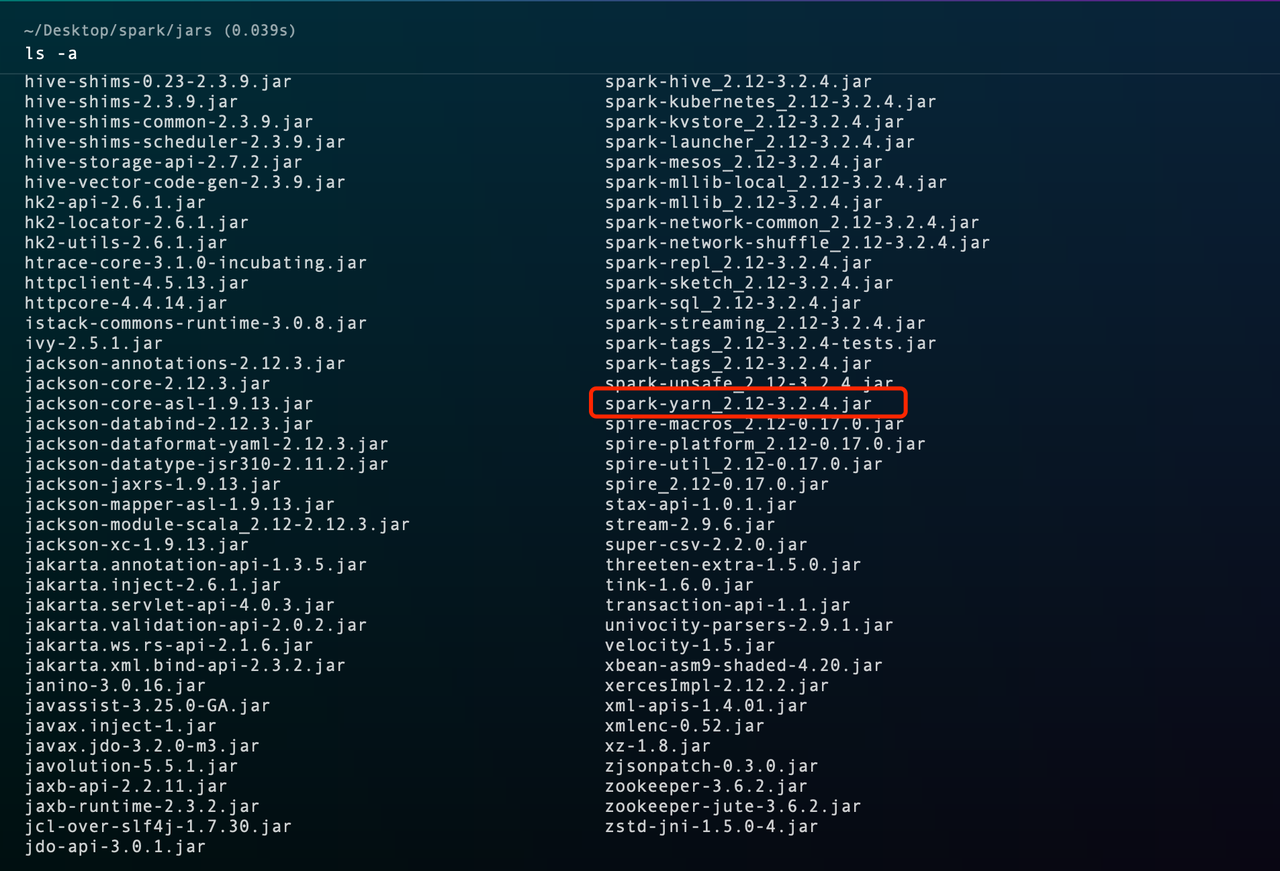
進入Spark安裝目錄的jars目錄下,查看以spark-yarn開頭的jar包,獲取Spark依賴包對應的Scala版本。示例如下:
spark-yarn_2.12-3.2.4.jar對應的Scala版本的為2.12。
無Spark環境
直接選擇Scala2.12對應的X2Doris安裝包即可。
下載X2Doris工具。
X2Doris官網地址:X2Doris工具。
wget https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/x2doris/selectdb-x2doris-1.0.4_2.12-bin.tar.gz解壓安裝包
tar -zxvf selectdb-x2doris-1.0.4_2.12-bin.tar.gz初始化元數據。
初始化X2Doris元數據的數據庫,主要有內置的h2內存數據庫和自建的MySQL兩種模式。
重要h2內存數據庫,系統重啟后會導致X2Doris元數據丟失。推薦您使用自建的MySQL。
自建MySQL
如果您需要持久化X2Doris元數據,可以選擇MySQL作為保存元數據的數據庫。
安裝MySQL。
sudo yum install mysql登錄MySQL。
mysql -h<IP> -P<port> -u<user_name> -p<password>;運行腳本。
運行mysql-schema.sql,完成表結構的初始化。
abs_path為X2Doris的安裝目錄
mysql-schema.sql的絕對路徑。source <abs_path>/mysql-schema.sql;運行完成后,MySQL實例下會自動創建一個名為
x2doris的數據庫,可通過show databases;查看。運行
mysql-data.sql,完成表數據的初始化。abs_path為X2Doris的安裝目錄
mysql-data.sql的絕對路徑。source <abs_path>/mysql-data.sql;
將X2Doris的數據庫類型修改為MySQL。
進入X2Doris的安裝目錄下的
conf目錄,修改application.yml將spring.profiles.active的值修改為mysql。vim application.yml
指定MySQL的連接信息。
進入X2Doris的安裝目錄下的
conf目錄,修改application-mysql.yml文件,配置數據源。vim application-mysql.yml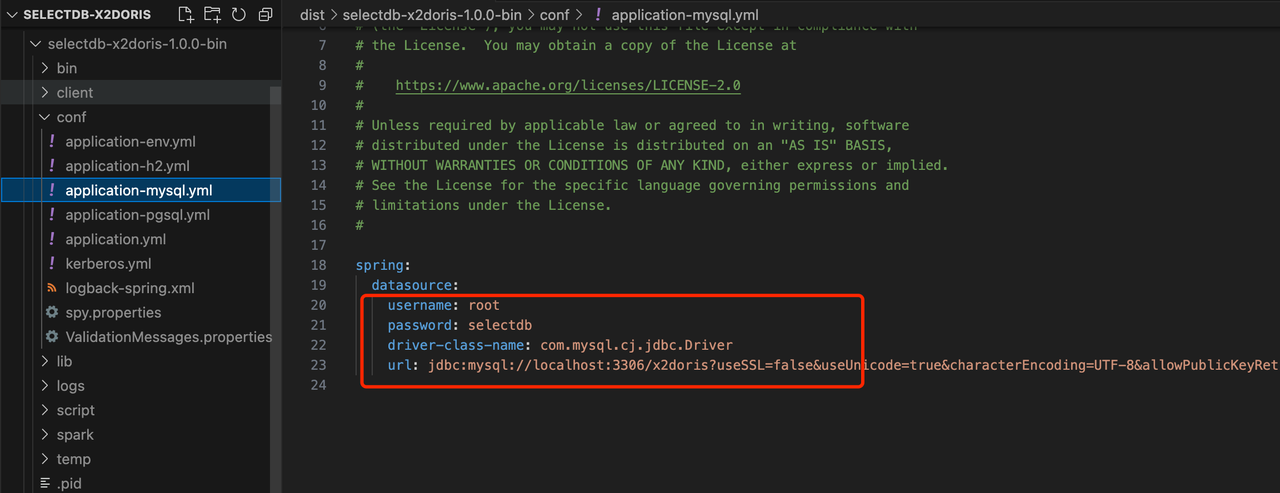
h2
X2Doris默認的h2是內存數據庫。
重要系統重啟后會導致X2Doris元數據丟失。
啟動X2Doris。
進入X2Doris安裝目錄下的
bin目錄,執行bash startup.sh。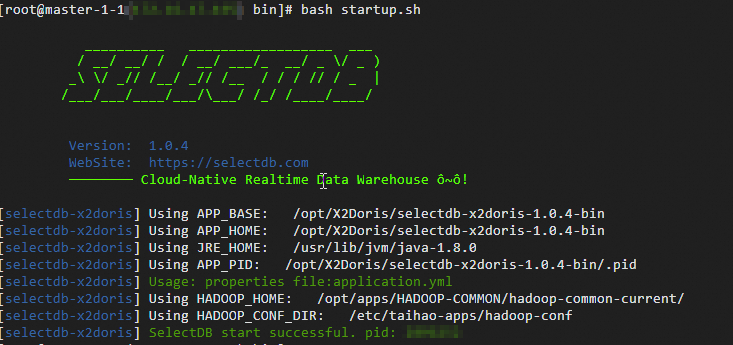
導入數據
前提條件
已將源數據的相關IP以及X2Doris部署服務器的IP添加至云數據庫 SelectDB 版的白名單,請參見設置白名單。
已開放X2Doris的訪問端口。
說明默認端口為9091。具體端口號,請查看X2Doris安裝目錄下的application.yml的配置。
注意事項
如果您的數據源是Hive數據源,請檢查安裝X2Doris所在機器的環境。具體環境要求,請參見環境要求。
操作步驟
配置獲取Hive元數據的方式。
通過修改X2Doris的配置文件
conf/application-hive.yaml,設置獲取Hive元數據方式。vim application-hive.yaml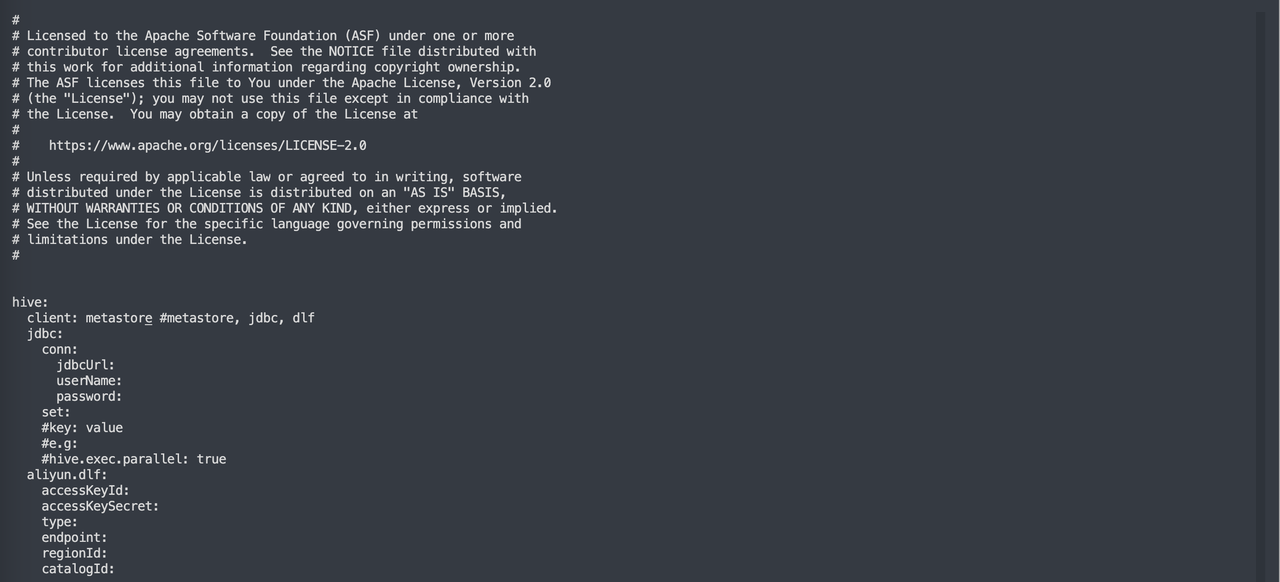
參數說明
參數名稱
說明
client
獲取Hive元數據的方式。
Metastore:默認的讀取Hive元數據的方式。如果您的Hive是標準的Apache Hive,建議您將client設置為Metastore。
jdbc:如果因為權限等問題,不能使用
metastore的方式,建議您嘗試使用JDBC的方式,將client設置為jdbc。dlf:如果您的Hive是阿里云的Hive,則需要設置client為
dlf。
jdbc
如果client配置了jdbc,則必須配置jdbc相關的參數。
jdbcurl:源數據Hive的jdbc連接串。
userName:Hive的用戶名。
password:登錄密碼。
aliyun.dlf
如果client配置了dlf,則必須配置dlf相關的參數。
accesskeyId:阿里云賬號AccessKey ID。
accessKeySeceret:阿里云賬號密鑰AccessKey Secret。
endpoint:dlf對外服務的訪問域名。
regionId:dlf數據中心所在的地域。
catalogId:dlf數據目錄。
登錄X2Doris控制臺。
默認訪問地址:
http://<IP>:9091。說明IP為安裝X2Doris服務器的IP地址。
9091是X2Doris的默認端口,如果您在application.yml 里修改了端口號,請替換為您設置的端口。
默認用戶名是
admin,密碼是selectdb。
系統設置。
在X2Doris控制臺左側導航欄,單擊系統設置,在系統設置面板,進行以下配置操作。
配置Hadoop user:單擊Hadoop user右側的編輯,在輸入框中輸入Hadoop user,單擊提交。
配置Spark Home:單擊Spark Home右側的編輯,在輸入框中輸入Spark Home,單擊提交。
配置Hive metastore uris:單擊Hive metastore uris右側的編輯,在輸入框中輸入Hive metastore uris,單擊提交。
說明要導入的數據源為Hive時,此項必須配置。
可通過
SET hive.metastore.uris;在Hive的控制臺獲取此配置項值。
配置Target doris info:單擊Target doris info右側的編輯,在Doris/SelectDB Cloud 目標端信息錄入彈出框,配置以下配置項。配置完成后,單擊確定。
配置項
說明
HTTP Nodes
HTTP協議訪問地址。
格式:
<ip>:<port>。說明您可以從云數據庫 SelectDB 版控制臺的實例詳情 > 網絡信息中獲取VPC地址(或公網地址)和HTTP協議端口。
當部署X2Doris的實例和云數據庫 SelectDB 版實例屬于同一VPC時,使用VPC地址;不屬于同一個VPC時,建議使用公網地址。
示例:
selectdb-cn-4xl3jv1****.selectdbfe.rds.aliyuncs.com:8080MySQL Nodes
JDBC連接串。
格式:
<ip>:<port>。說明您可以從云數據庫 SelectDB 版控制臺的實例詳情 > 網絡信息中獲取VPC地址(或公網地址)和HTTP協議端口。
當部署X2Doris的實例和云數據庫 SelectDB 版實例屬于同一VPC時,使用VPC地址;不屬于同一個VPC時,建議使用公網地址。
您可以從云數據庫 SelectDB 版控制臺的實例詳情 > 網絡信息中獲取VPC地址(或公網地址)和MySQL協議端口。
示例:
selectdb-cn-4xl3jv1****.selectdbfe.rds.aliyuncs.com:9030User
云數據庫 SelectDB 版實例的用戶名。
Password
云數據庫 SelectDB 版實例用戶的密碼。
創建作業。
在左側導航欄,單擊作業中心,進入作業中心頁面。
將鼠標懸浮在作業中心數據列表右上方的新增作業,選擇目標數據源,進入作業配置頁面。
在頁面左側區域,選擇目標源數據庫。
配置字段映射,單擊下一步。
配置項
說明
DORIS 字段類型
默認系統會自動識別Doris與Hive字段類型的對應。
說明默認系統會自動識別。
指定Doris表對應的數據類型,特別是string類型。
DUPLICATE KEY
指明底層數據的排序列。
說明至少有一個字段設置了此項。
DISTRIBUTED BY
指明底層數據的分桶列。
說明至少有一個字段設置了此項。
配置分區映射。
如果Hive原表中的分區字段類型是
STRING,則可以根據數據實際類型判斷是否需要將對應的云數據庫 SelectDB 版目標表的字段類型轉成時間類型。如需轉換,則需要設置分區的區間。配置項
說明
DORIS 字段類型
默認系統會自動識別Doris與Hive字段類型的對應。
說明默認系統會自動識別。
請指定doris表對應的數據類型,特別是string類型。
DUPLICATE KEY
指明底層數據的排序列。
說明至少有一個字段設置了此項。
DISTRIBUTED BY
指明底層數據的分桶列。
說明至少有一個字段設置了此項。
創建表。
如果您在SelectDB上已經創建好了對應的表,單擊跳過建表,進入作業設置。
如果您還未在SelectDB上已經創建好了對應的表,單擊去建表,確認Doris DDL 建表語句后,單擊創建Doris表,單擊下一步,進入作業設置。
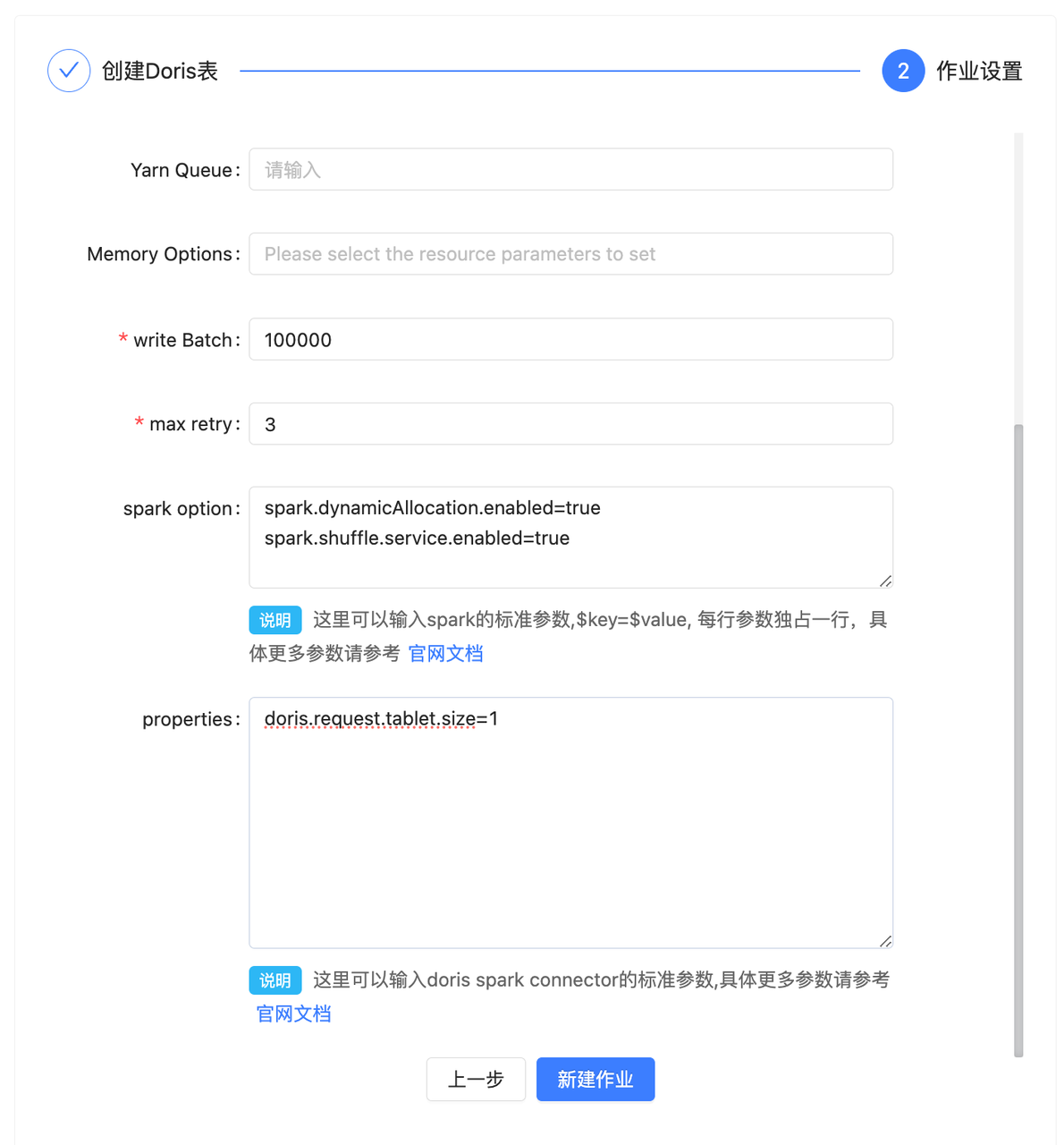
配置以下作業設置項,單擊新建作業。
配置項
說明
作業名稱
自動生成,數據導入任務的名稱。
作業標簽
自動生成,數據導入任務的標簽。
Master
需要選擇是local模式還是yarn模式,這里是指的X2Doris的任務運行的方式,這個根據實際情況調整。
Yarn 隊列
Spark任務運行所使用的隊列資源。
資源參數
這里需要選擇Spark任務的一些內存參數,如executor和driver的core的數量和內存大小,這個根據實際情況進行調整。
寫入批次
數據刷寫時的批次大小,這個可以根據實際數據量調整大小,如果導入的數據量比較大,建議該值調整為500000以上。
失敗重試
任務失敗的重試次數,如果網絡情況不理想,可以適當增大此參數。
Spark 參數
Spark的自定義參數,如果需要增加Spark任務的其他參數,可以在這里添加,以
key=value的形式增加即可。這里可以輸入spark的標準參數,具體更多參數請參考Application Properties。
連接配置器
數據導入時,如果有針對數據源讀取或者Doris數據寫入的一些優化參數,可以在這里編寫,具體的參數描述可以看對應的Spark connector的官方文檔。
這里可以輸入doris spark connector的標準參數,具體更多參數請參考通用配置項。
啟動同步作業。
在頁面左側導航欄,單擊作業中心。
在作業中心數據列表,找到目標作業,單擊操作列的啟動按鈕
 。
。在啟動作業彈窗,配置以下配置項。
配置項說明
配置項
參數說明
示例值
查詢條件
根據條件查詢要導入的數據。
說明不需要寫
WHERE關鍵字,只需要寫過濾邏輯。name='Alice'
清空數據
是否刪除目標數據庫的表數據。
警告該操作存在風險,請謹慎操作。
OFF(默認):不刪除。
ON:刪除。
OFF
單擊確定。
查看作業。
在左側導航欄,單擊作業中心,進入作業中心頁面。
找到目標作業,可查看作業的遷移進度、執行狀態等信息。
導入非Hive源數據
安裝X2Doris
安裝環境
本文以Linux系統為例,安裝X2Doris工具。您在實際使用中,請根據您的系統和使用環境選擇合適的命令。
操作步驟
選擇X2Doris工具版本。
有Spark環境
進入Spark安裝目錄的jars目錄下,查看以spark-yarn開頭的jar包,獲取Spark依賴包對應的Scala版本。示例如下:
spark-yarn_2.12-3.2.4.jar對應的Scala版本的為2.12。
無Spark環境
直接選擇Scala2.12對應的X2Doris安裝包即可。
下載X2Doris工具。
X2Doris官網地址:X2Doris工具。
wget https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/x2doris/selectdb-x2doris-1.0.4_2.12-bin.tar.gz解壓安裝包
tar -zxvf selectdb-x2doris-1.0.4_2.12-bin.tar.gz初始化元數據。
初始化X2Doris元數據的數據庫,主要有內置的h2內存數據庫和自建的MySQL兩種模式。
重要h2內存數據庫,系統重啟后會導致X2Doris元數據丟失。推薦您使用自建的MySQL。
自建MySQL
如果您需要持久化X2Doris元數據,可以選擇MySQL作為保存元數據的數據庫。
安裝MySQL。
sudo yum install mysql登錄MySQL。
mysql -h<IP> -P<port> -u<user_name> -p<password>;運行腳本。
運行mysql-schema.sql,完成表結構的初始化。
abs_path為X2Doris的安裝目錄
mysql-schema.sql的絕對路徑。source <abs_path>/mysql-schema.sql;運行完成后,MySQL實例下會自動創建一個名為
x2doris的數據庫,可通過show databases;查看。運行
mysql-data.sql,完成表數據的初始化。abs_path為X2Doris的安裝目錄
mysql-data.sql的絕對路徑。source <abs_path>/mysql-data.sql;
將X2Doris的數據庫類型修改為MySQL。
進入X2Doris的安裝目錄下的
conf目錄,修改application.yml將spring.profiles.active的值修改為mysql。vim application.yml指定MySQL的連接信息。
進入X2Doris的安裝目錄下的
conf目錄,修改application-mysql.yml文件,配置數據源。vim application-mysql.yml
h2
X2Doris默認的h2是內存數據庫。
重要系統重啟后會導致X2Doris元數據丟失。
啟動X2Doris。
進入X2Doris安裝目錄下的
bin目錄,執行bash startup.sh。
導入數據
前提條件
已將源數據的相關IP以及X2Doris部署服務器的IP添加至云數據庫 SelectDB 版的白名單,請參見設置白名單。
已開放X2Doris的訪問端口。
說明默認端口為9091。具體端口號,請查看X2Doris安裝目錄下的application.yml的配置。
操作步驟
登錄X2Doris控制臺。
默認訪問地址:
http://<IP>:9091。說明IP為安裝X2Doris服務器的IP地址。
9091是X2Doris的默認端口,如果您在application.yml 里修改了端口號,請替換為您設置的端口。
默認用戶名是
admin,密碼是selectdb。
系統設置。
在X2Doris控制臺左側導航欄,單擊系統設置,在系統設置面板,進行以下配置操作。
(可選)配置Hadoop user:單擊Hadoop user右側的編輯,在輸入框中輸入Hadoop user,單擊提交。
(可選)配置Spark Home:單擊Spark Home右側的編輯,在輸入框中輸入Spark Home,單擊提交。
(可選)配置Hive metastore uris:單擊Hive metastore uris右側的編輯,在輸入框中輸入Hive metastore uris,單擊提交。
配置Target doris info:單擊Target doris info右側的編輯,在Doris/SelectDB Cloud 目標端信息錄入彈出框,配置以下配置項。配置完成后,單擊確定。
配置項
說明
HTTP Nodes
HTTP協議訪問地址。
格式:
<ip>:<port>。說明您可以從云數據庫 SelectDB 版控制臺的實例詳情 > 網絡信息中獲取VPC地址(或公網地址)和HTTP協議端口。
當部署X2Doris的實例和云數據庫 SelectDB 版實例屬于同一VPC時,使用VPC地址;不屬于同一個VPC時,建議使用公網地址。
示例:
selectdb-cn-4xl3jv1****.selectdbfe.rds.aliyuncs.com:8080MySQL Nodes
JDBC連接串。
格式:
<ip>:<port>。說明您可以從云數據庫 SelectDB 版控制臺的實例詳情 > 網絡信息中獲取VPC地址(或公網地址)和HTTP協議端口。
當部署X2Doris的實例和云數據庫 SelectDB 版實例屬于同一VPC時,使用VPC地址;不屬于同一個VPC時,建議使用公網地址。
您可以從云數據庫 SelectDB 版控制臺的實例詳情 > 網絡信息中獲取VPC地址(或公網地址)和MySQL協議端口。
示例:
selectdb-cn-4xl3jv1****.selectdbfe.rds.aliyuncs.com:9030User
云數據庫 SelectDB 版實例的用戶名。
Password
云數據庫 SelectDB 版實例用戶的密碼。
添加數據源。
在左側導航欄,單擊數據源,進入數據源頁面。
將鼠標懸浮在數據源數據列表右上方的新增數據源,選擇目標數據源。
根據配置面板,完成配置項配置,單擊確定。
創建作業。
在左側導航欄,單擊作業中心,進入作業中心頁面。
將鼠標懸浮在作業中心數據列表右上方的新增作業,選擇目標數據源,進入作業配置頁面。
在請選擇數據源彈出框,找到目標數據源,單擊使用列的
。在頁面左側區域,選擇目標源數據。
說明選擇一張表,也可以選擇多張,或者整庫。
選擇單表時,頁面右側會出現創建表的DDL語句。
選擇多表則使用默認生成策略生成的DDL,右側不會出現DDL語句。
根據您的需求,單擊目標按鈕,進入作業設置項。
跳過建表:用于要遷移的表在云數據庫 SelectDB 版目標端已經存在,則可以跳過建表。
只建表:用于只創建表,不創建遷移作業。
創建表&作業:用于同時創建表和遷移作業。
配置以下作業設置項,單擊新建作業。
配置項
說明
作業名稱
數據遷移任務的名稱。
說明自動生成,無需手動輸入。
作業標簽
數據導入任務的標簽。
說明自動生成,無需手動輸入。
Master
X2Doris任務運行的方式。
說明如果安裝X2Doris的服務器上有Hadoop和yarn環境,就配置為集群模式yarn,否則配置為單機模式local。
Yarn 隊列
Spark任務運行所使用的隊列資源。
資源參數
Spark任務的內存參數。
例如executor和driver的core的數量和內存大小。更多參數,請參見Spark Configuration。
寫入批次
數據刷寫時的批次大小。
如果導入的數據量比較大,建議該值調整為500000以上。
失敗重試
任務失敗的重試次數。
如果網絡情況不理想,可以適當增大此參數。
Spark 參數
Spark的自定義參數。
說明如果需要增加Spark任務的其他參數,可以在這里以
key=value的形式進行添加。更多參數,請參見Application Properties。連接配置器
導入數據時,如果有針對數據源讀取或者SelectDB數據寫入的一些優化參數。例如數據源是Doris時,參數詳情,請參見Spark Doris Connector。
啟動同步作業。
在頁面左側導航欄,單擊作業中心。
在作業中心數據列表,找到目標作業,單擊操作列的啟動按鈕
。在啟動作業彈窗,配置以下配置項。
配置項說明
配置項
參數說明
示例值
查詢條件
根據條件查詢要導入的數據。
說明不需要寫
WHERE關鍵字,只需要寫過濾邏輯。name='Alice'
清空數據
是否刪除目標數據庫的表數據。
警告該操作存在風險,請謹慎操作。
OFF(默認):不刪除。
ON:刪除。
OFF
單擊確定。
在左側導航欄,單擊作業中心,進入作業中心頁面。
找到目標作業,可查看作業的遷移進度、執行狀態等信息。
查看作業。
在左側導航欄,單擊作業中心,進入作業中心頁面。
找到目標作業,可查看作業的遷移進度、執行狀態等信息。
參數優化指南
在源數據是Doris或StarRocks導入云數據庫 SelectDB 版的場景中,如果您的Doris和StarRocks資源比較空閑,可以進一步優化讀取速度。您可以在創建作業的屬性設置設置以下參數:
doris.request.tablet.size=1 #如果數據源是 doris
starrocks.request.tablet.size=1 #如果數據源是 starrocks該參數的含義是一個RDD Partition對應的Tablet個數。此數值越小,會生成越多的Partition,從而提升了Spark的并行度,但同時會對Doris或StarRocks造成更大的壓力。
常見問題
如何定位任務失敗原因?
當數據導入任務失敗后,優先排查安裝X2Doris程序的運行日志,對應目錄在X2Doris安裝目錄下的log目錄,可以查看selectdb.out來觀察和定位程序運行情況。
如果在查看上述日志后,仍未解決問題,請準備日志以及該遷移任務運行的上下文背景,通過工單定位問題。
添加Hive數據源失敗了怎么辦?
在添加Hive數據源時,系統會自動檢測Hive環境的連接情況,如果Hive連接失敗,會有以下錯誤提示。
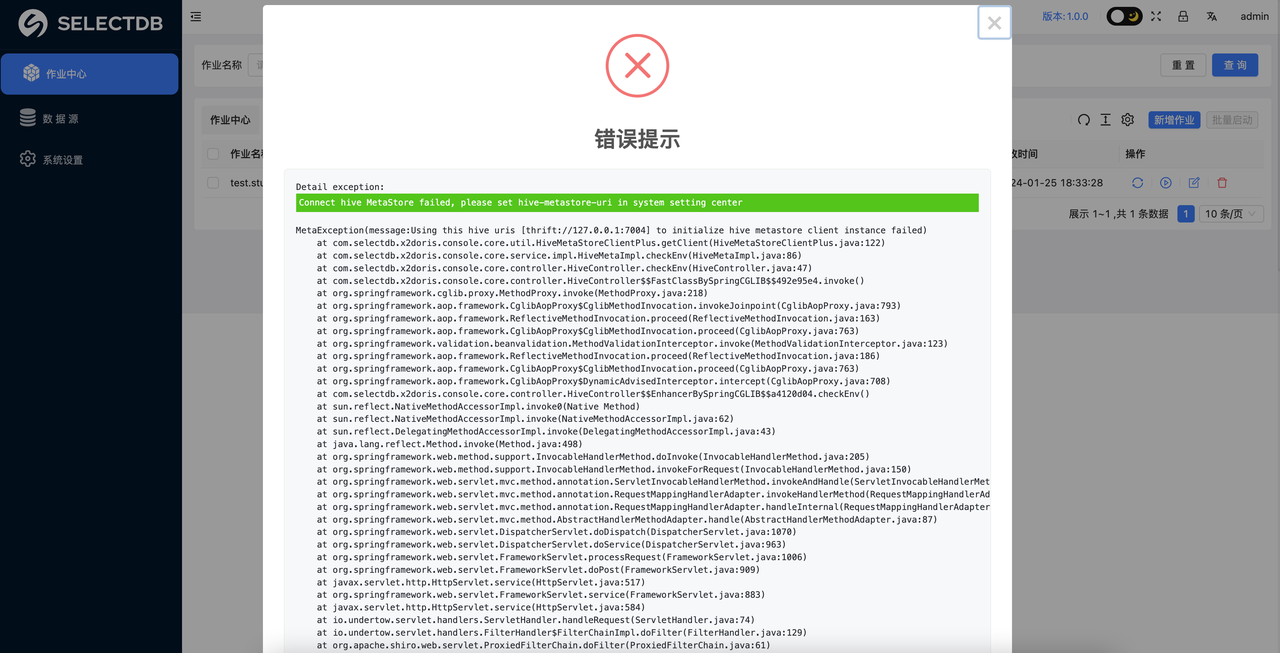
需要檢查系統設置里Hive metastore uris和當前X2Doris部署的服務器通訊是否正常。