導致阿里云Elasticsearch(簡稱ES)的負載不均問題的原因很多,目前主要包括shard設置不合理、segment大小不均、冷熱數據需求、負載均衡及多可用區架構部署的長連接不釋放等。本文介紹ES集群負載不均問題的分析方法及解決方案。
問題現象
節點間磁盤使用率差距不大,監控中節點CPU使用率或load_1m呈現明顯的負載不均衡現象。
節點間磁盤使用率差距很大,監控中節點CPU使用率或load_1m呈現明顯的負載不均衡現象。
問題原因
- 重要
大多數負載不均問題是由于shard設置不合理導致,建議優先排查。
存在典型的冷熱數據需求場景。
重要冷熱數據場景(例如查詢中添加了routing、查詢頻率較高的熱點數據)必然導致數據出現負載不均。
采用負載均衡及多可用區架構部署時,由于長連接不釋放可能會導致流量不均(很少出現),詳情請參見長連接不均勻。
其他情況導致的負載不均問題,請聯系阿里云技術支持工程師排查。
Shard設置不合理
場景
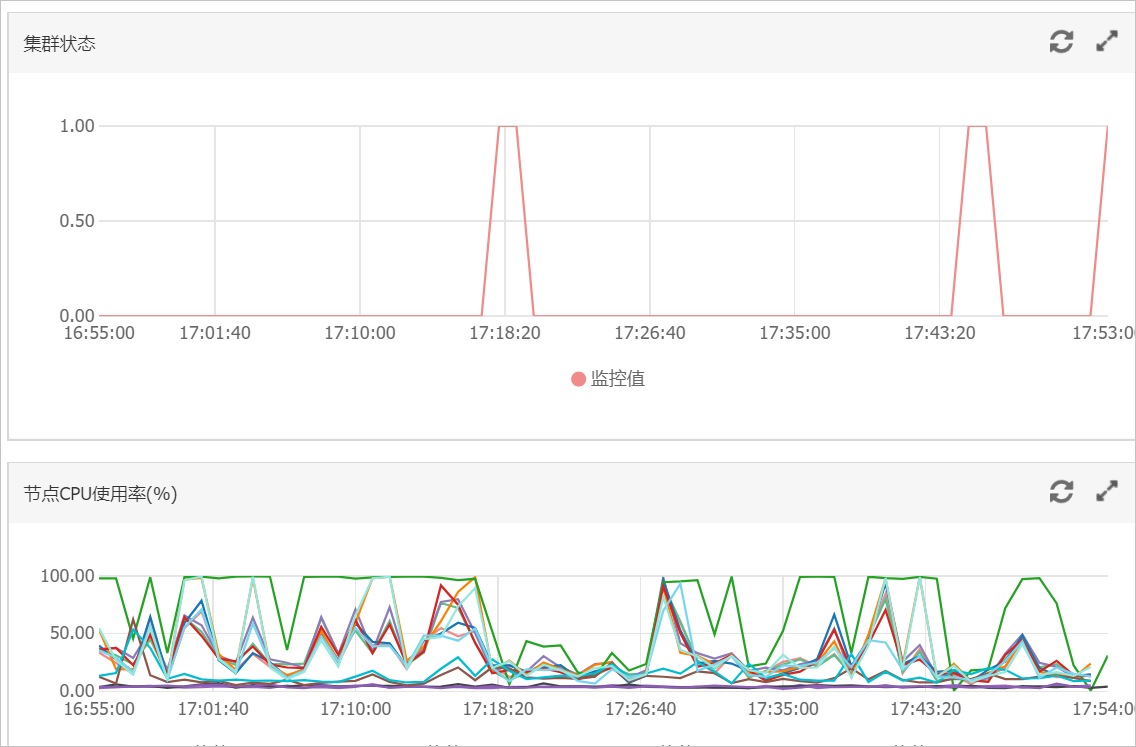
A公司有一個阿里云ES實例,該實例配置為:3個主節點16核32GB、9個數據節點32核64GB,主要數據保存在test索引上。當在業務高峰期的時候(16:21~18:00左右),查詢QPS為2000左右(查詢中沒有冷熱數據分離)、寫入QPS為1000、2個節點的CPU達到100,負載過高影響ES服務。
分析
優先檢查查詢期間的網絡及ECS情況。如果ECS環境正常,再查看網絡流量監控。
根據監控結果發現異常期間(16:21)網絡請求上升,查詢QPS上升,對應的CPU節點負載大幅增高。結合查詢策略,初步判斷負載高的節點主要承擔了查詢請求。
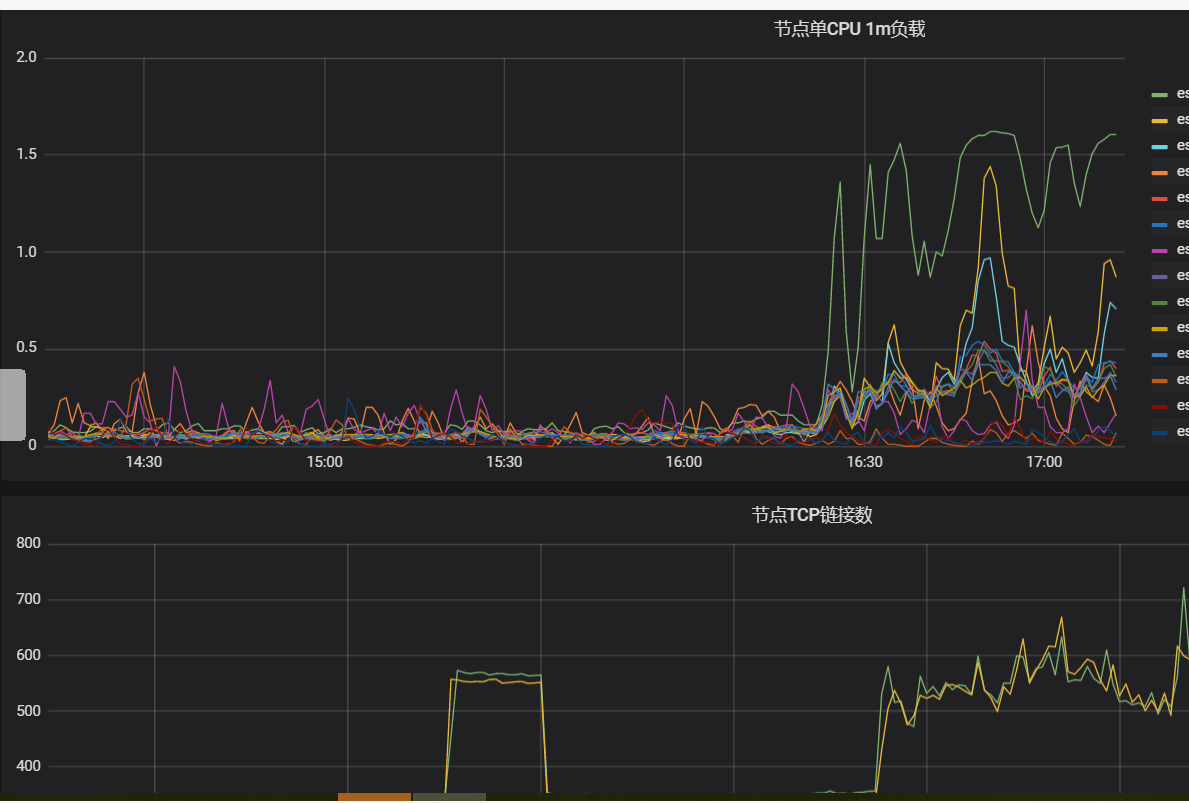
使用
GET _cat/shards?v,查看索引的shard信息。從結果可以看到test索引的shard在負載高的節點上呈現的數量較多,說明shard分配不均;然后查看磁盤使用率監控圖,顯示負載高的節點使用率比其他節點高。由此可以得出,shard分配不均衡導致存儲不均,在業務查詢或寫入中,存儲高的節點承擔主要的查詢和寫入。
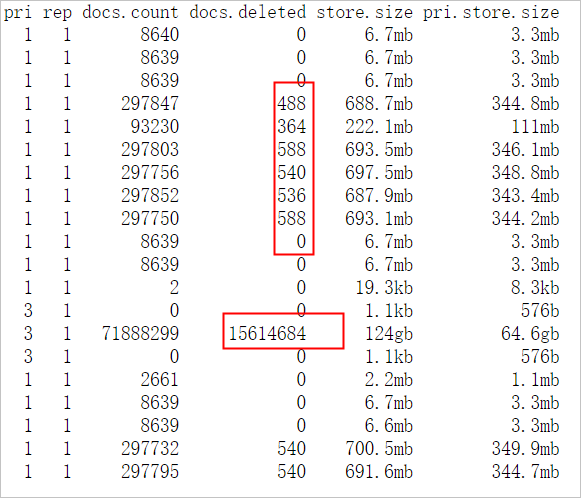
使用
GET _cat/indices?v,查看索引信息。從結果可以看到索引的主shard數量為5,副shard數量為1。結合集群配置,發現存在節點shard分配不均的現象,其次集群中存在被刪除的文檔。ES在檢索過程中也會檢索.del文件,然后過濾標記有.del的文檔,大大地降低檢索效率,耗費規格資源,建議在業務低峰期進行force merge。
查看主日志及searching慢日志。
從結果可以看到查詢請求都是普通的term查詢,且主日志正常,可以排除ES集群本身出現問題以及存在消耗CPU的查詢語句的情況。
總結
通過以上分析,可以判斷CPU負載不均主要是由于shard分布不均導致的。重新分配分片,確保主shard數與副shard數之和是集群數據節點的整數倍,集群的CPU負載趨于穩定。優化后的CPU趨勢圖如下。
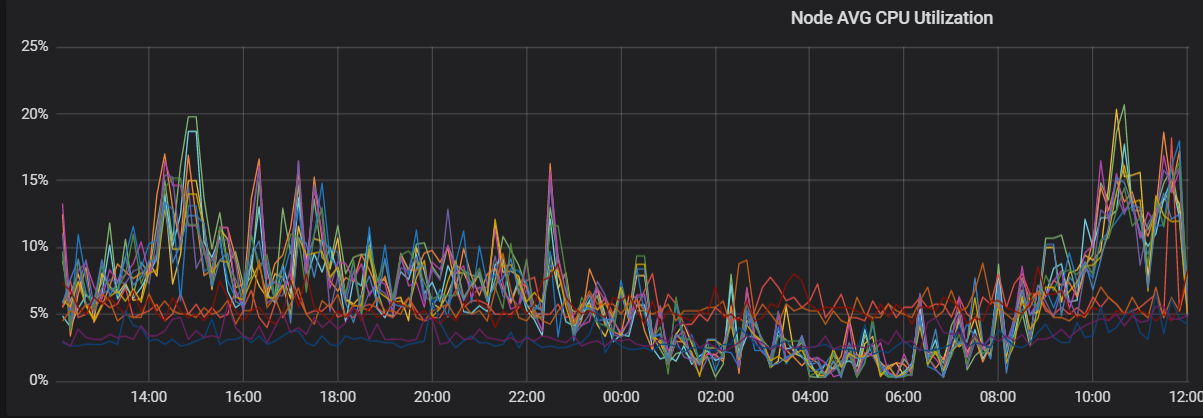
解決方案
在創建索引時,合理規劃shard,詳情請參見Shard評估建議。
Shard評估建議
Shard大小和數量是影響ES集群穩定性和性能的重要因素之一。ES集群中任何一個索引都需要有一個合理的shard規劃。合理的shard規劃能夠防止因業務不明確,導致分片龐大消耗ES本身性能的問題。
ES 7.x以下版本的索引默認包含5個主shard,1個副shard;ES 7.x 及以上版本的索引默認包含1個主shard,1個副shard。
建議在小規格節點下,單個shard大小不要超過30GB。對于更高規格的節點,單個shard大小不要超過50GB。
對于日志分析或者超大索引場景,建議單個shard大小不要超過100GB。
建議shard的個數(包括副本)要盡可能等于數據節點數,或者是數據節點數的整數倍。
說明主分片不是越多越好,因為主分片越多,ES性能開銷也會越大。
建議單節點shard總數按照單節點內存*30進行評估,如果shard數量太多,極易引起文件句柄耗盡,導致集群故障。
建議單個節點上同一索引的shard個數不要超5個。
如果您使用了自動創建索引功能,可通過設置場景模板,調整索引shard均衡,詳情請參見修改場景化配置模板。
Segment大小不均
場景
A公司ES集群忽然出現單個節點CPU飆升,影響查詢性能。查詢主要集中在test索引、shard設置為3主1副、shard分配均衡、索引中存在大量的delete.doc,且優先排除了底層主機問題。
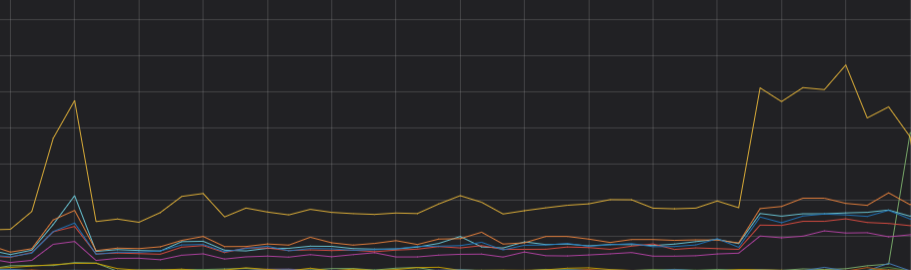
分析
在查詢body中添加
"profile": true。根據結果可以看到test索引的1號shard查詢時間比其他shard長。
查詢中分別指定
preference=_primary和preference=_replica,body中添加"profile": true,分別查看主副shard查詢消耗的時間。根據結果定位出索引的1號shard耗時主要體現在主shard上,判斷和shard有關。
使用
GET _cat/segments/index?v&h=shard,segment,size,size.memory,ip及GET _cat/shards?v,查看索引的1號shard的信息。從結果可以看到索引的1號shard中存在比較大的segment,且doc數量比正常的副shard多。由此可以判斷負載不均與segment大小不均有關。
說明造成主副shard的doc數量不一致的原因有很多,例如以下兩種情況:
如果一直有doc寫入shard,由于主副數據同步有一定延遲,會導致數據不一致。但一般停止寫入后,主副doc數量是一致的。
如果使用自動生成docid的方式寫入doc,由于主shard寫入完成后會轉發請求到副shard,因此在此期間,如果執行了刪除操作,例如并行發送Delete by Query請求刪除了主分片上剛寫完的doc,那么副shard也會執行此刪除請求;然后主shard又轉發寫入請求到副shard上,對于自動生成的id,doc將直接寫入副shard,不進行檢查,最終導致主副shard的doc數量不一致,同時在
doc.delete中也可以看到主shard中存在大量的刪除文檔。
解決方案(任選一種)
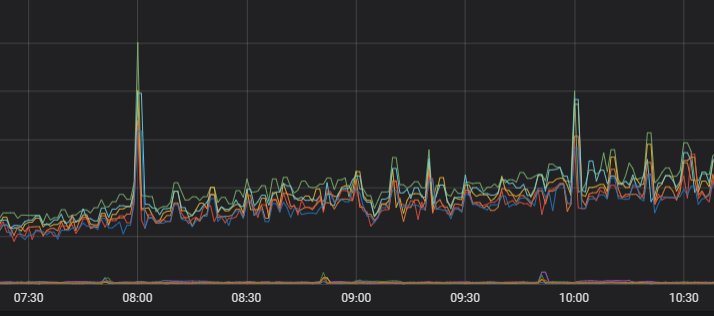
在業務低峰期進行force merge,將緩存中的delete.doc徹底刪除,將小segment合并成大segment。
重啟主shard所在節點,觸發副shard升級為主shard。并且重新生成副shard,副shard復制新的主shard中的數據,保持主副shard的segment一致。
優化后的負載監控圖如下。
長連接不均勻
場景
A公司為實現ES集群跨區域容災部署,分別在b區和c區部署高可用架構,在持續提供業務操作時,集群中c區節點負載明顯比b區高,并且已經排除數據分配不均及硬件問題。
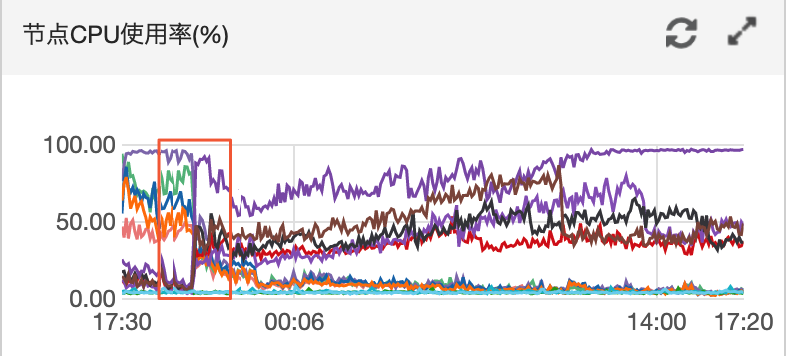
分析
觀察近4天兩區域節點的CPU監控。
根據結果可以看到兩區域節點CPU出現較大負載變動。
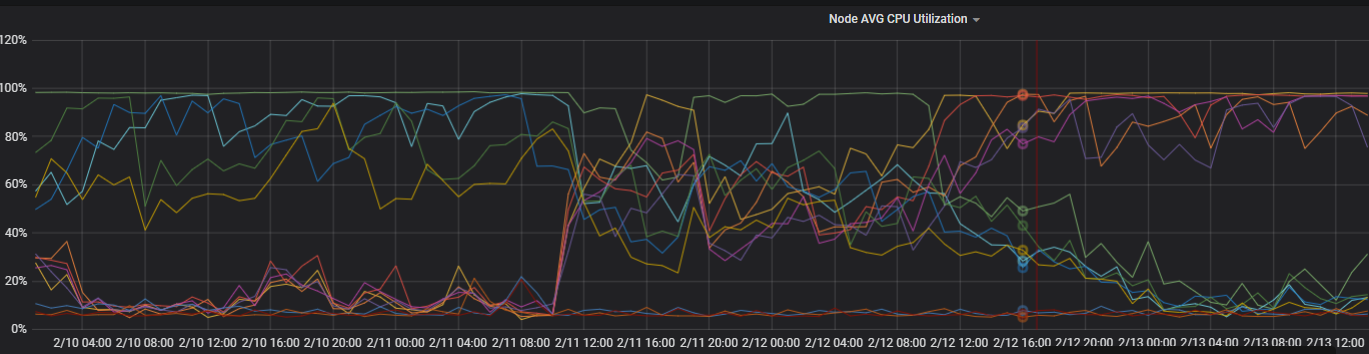
觀察節點TCP連接。
根據結果可以看到兩個區域下的連接數相差很大。判定與網絡不均相關。
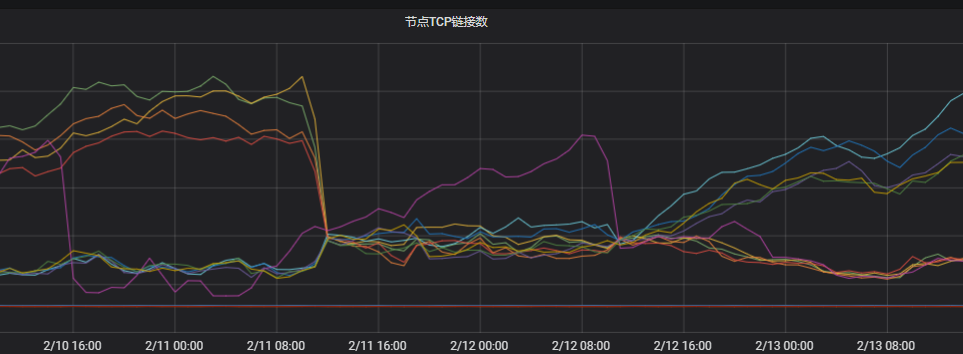
排查客戶端的連接情況。
客戶端使用長連接,新建連接比較少,恰恰命中了多可用區網絡獨立調度的風險(網絡服務是基于連接數獨立調度的,每個調度單元會選擇自己認為最優的節點進行創建,獨立調度的性能會更高,但獨立調度的風險是當新連接比較少的時候,有一定概率出現大部分調度單元都選擇相同的節點去建立連接)。ES的協調節點對于請求的轉發是同區域優先,即ES將請求轉到其他區域的可能性較小,這樣就導致當前區域出現負載不均的問題。
解決方案(任選一種)
客戶端配置
httpClientBuilder.setConnectionTimeToLive()。例如,配置連接有效時長為5分鐘:httpClientBuilder.setConnectionTimeToLive(5, TimeUnit.MINUTES)。詳細信息,請參見HttpAsyncClientBuilder。說明客戶端配置鏈接有效時長需要使用ES推薦的httpClientBuilder.setConnectionTimeToLive(),配置別的參數效果可能不太明顯,例如:httpClientBuilder.setKeepAliveStrategy()。
并發重啟客戶端,重新建立連接。
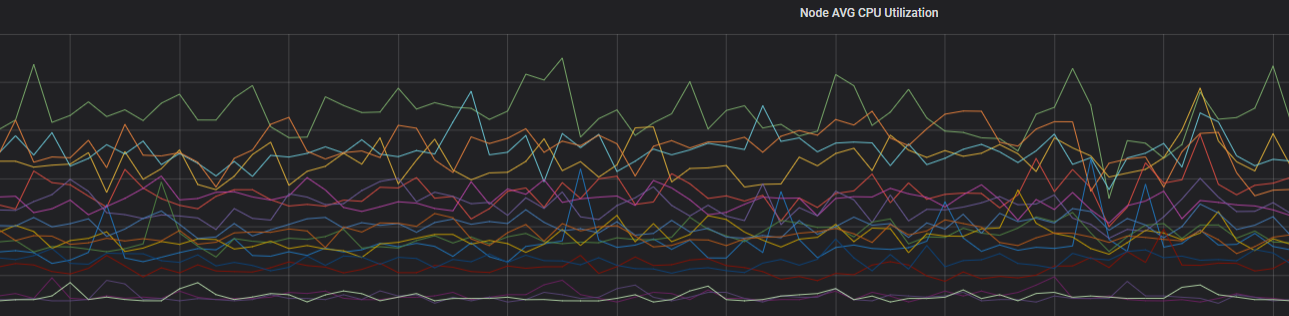
使用單獨的協調節點,通過工作職責劃分來降低風險。使用協調節點轉發復雜流量,即使負載高,也不會影響到后面的數據節點。
優化后的負載監控圖如下。
單個索引分片不均勻
場景:觀察每個節點分片較均衡,但是業務索引在負載較高的節點分布的分片數比較多或承載單分片數據量多。
解決方案:設置控制每個節點上分配給單個索引的最大分片數量index.routing.allocation.total_shards_per_node,參數取值計算公式為
(主+副本數)/數據節點個數,參數值需為整數,小數向上取整。PUT index_name/_settings { { "index.routing.allocation.total_shards_per_node" : "3" } }